Ļ░£ ņÜö
ņØśļŻī ļŹ░ņØ┤Ēä░ļŖö ļŹ░ņØ┤Ēä░ ĻĄ¼ņĪ░, ĒśĢņŗØņØś ņØ┤ņ¦łņä▒, ļŹ░ņØ┤Ēä░ņØś ņ¦łĻ│╝ ņ¢æ ļō▒ ĻĖ░ņłĀņĀüņØĖ ņ¢┤ļĀżņøĆĻ│╝ ĻĖ░Ļ┤ĆņØś ĒŚłļØĮ, Ļ░£ņØĖ ņĀĢļ│┤ļ│┤ĒśĖ ļ¼ĖņĀ£ ļō▒ ļ▓ĢņĀü ļ¼ĖņĀ£ ĻĘĖļ”¼Ļ│Ā ĒāĆņØĖņŚÉĻ▓ī ņĀ£Ļ│ĄĒĢśļŖö ļŹ░ņØ┤Ēä░Ļ░Ć ņ×ÉņŗĀņŚÉĻ▓ī ļČłļ”¼ĒĢśĻ▓ī ņé¼ņÜ®ļÉĀņ¦Ć ļ¬©ļźĖļŗżļŖö ļæÉļĀżņøĆ ļō▒ņØś ļ¼ĖņĀ£ļĪ£ ņŚ░ĻĄ¼ņ×É Ļ░ä Ļ│Ąņ£ĀĻ░Ć ņēĮņ¦Ć ņĢŖļŗż. Ēśäņ×¼Ļ╣īņ¦Ć ļīĆļČĆļČäņØś ĻĖ░Ļ┤Ć Ļ░ä Ļ│ĄļÅÖ ņŚ░ĻĄ¼ļŖö ĻĘ╣Ē׳ ņØ╝ļČĆņØś ĒÖśņ×É ļŹ░ņØ┤Ēä░ļź╝ ņŚ░ĻĄ¼ ņŻ╝ļÅä ĻĖ░Ļ┤ĆĻ│╝ Ļ│Ąņ£ĀĒĢ©ņ£╝ļĪ£ņŹ© ņ¦äĒ¢ēĒĢśņśĆļŖöļŹ░, ĒĢ£ ļ▓łņØś Ļ│ĄļÅÖ ņŚ░ĻĄ¼ļź╝ ņ£äĒĢśņŚ¼ ļ¦ēļīĆĒĢ£ ļģĖļĀźĻ│╝ ņŗ£Ļ░ä, ņ×ÉĻĖłņØ┤ ļōżņ¢┤Ļ░ĆļŖö ĒśäņŗżņĀüņØĖ ļ¼ĖņĀ£ņÖĆ Ļ░£ņØĖ ņĀĢļ│┤ Ļ│Ąņ£Āļź╝ ņĀ£ĒĢ£ĒĢśļŖö ļ▓ĢņĀü/ņĀ£ļÅäņĀü ļ¼ĖņĀ£ļōżņØ┤ ņ׳ļŗż[1]. ņĄ£ĻĘ╝ ņØ┤ļ¤░ ņĀ£ņĢĮņØä ĻĘ╣ļ│ĄĒĢśĻĖ░ ņ£äĒĢśņŚ¼ Ļ│ĄĒåĄ ļŹ░ņØ┤Ēä░ ļ¬©ļŹĖ(common data model, CDM)ņØä ņØ┤ņÜ®ĒĢ£ ļČäņé░ņŚ░ĻĄ¼ļ¦Ø(distributed research network)ņØ┤ ņŻ╝ļ¬®ļ░øĻ│Ā ņ׳ļŗż.
ņØśļŻī ļŹ░ņØ┤Ēä░ Ēæ£ņżĆĒÖöņØś ĒĢäņÜöņä▒ ļ░Å ļČäņé░ņŚ░ĻĄ¼ļ¦ØņØś ļīĆļæÉ
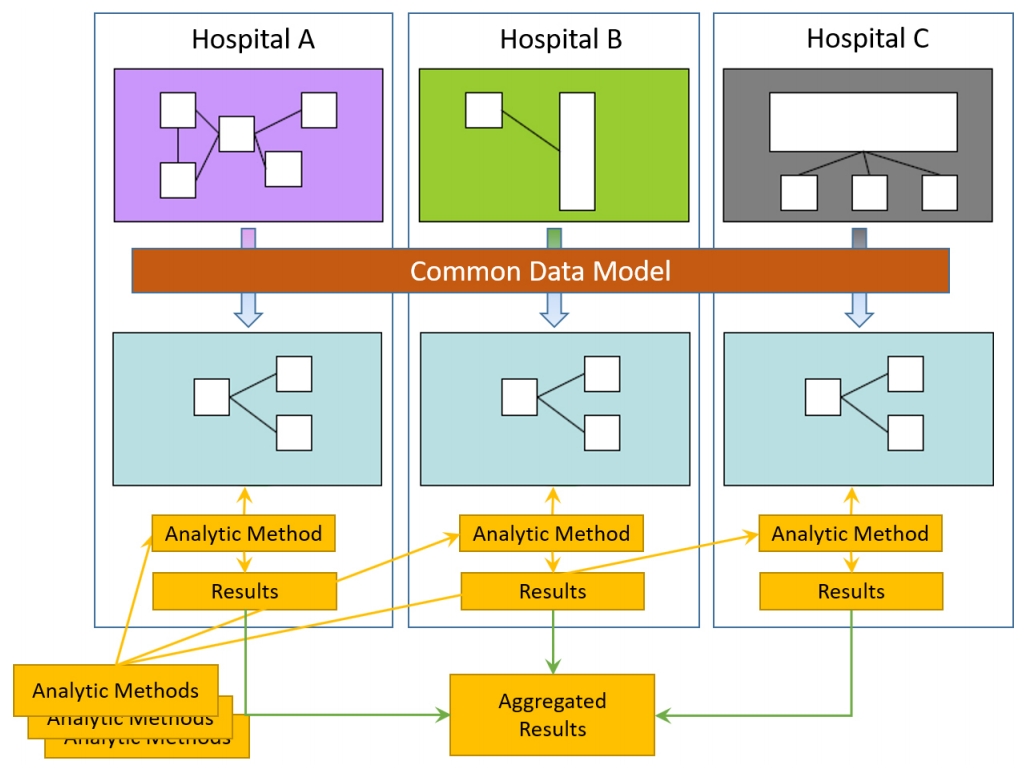
ļČäņé░ņŚ░ĻĄ¼ļ¦ØņØĆ ņøÉļ│Ė ļŹ░ņØ┤Ēä░ņØś Ļ│Ąņ£Ā ņŚåņØ┤ ļČäņé░ļÉ£ ĒśĢĒā£ļĪ£ ļŹ░ņØ┤Ēä░ļź╝ Ļ┤Ćļ”¼ĒĢśļ®┤ņä£ ĻĖ░Ļ┤Ć ļé┤ņŚÉņä£ ļČäņäØĒĢ£ Ļ▓░Ļ│╝ļ¦ī Ļ│Ąņ£ĀĒĢśļŖö ļ░®ņŗØņØ┤ļŗż. ņ”ē, Ļ░ü ļ│æņøÉņØś ĒÖśņ×ÉņĀĢļ│┤ļź╝ Ēæ£ņżĆĒÖö ļ░Å Ļ░Ćļ¬ģĒÖöĒĢ£ Ēøä ļŹ░ņØ┤Ēä░ļź╝ ļ│æņøÉ ĒÅÉņćäļ¦Ø ņĢłņŚÉ ļæÉĻ│Ā ņé¼ņÜ®ņ×ÉņØś ņÜöņ▓ŁņŚÉ ļö░ļØ╝ņä£ ĻĖ░Ļ┤Ć ņĢłņŚÉņä£ RņØ┤ļéś ĒīīņØ┤ņŹ¼ ļō▒ ĒöäļĪ£ĻĘĖļש/ļČäņäØņĮöļō£ļź╝ ņŗżĒ¢ēĒĢśņŚ¼ ļČäņäØļÉ£ ņÜöņĢĮ ņ¦æĒĢ®ņĀĢļ│┤(ĒÅēĻĘĀ, ĒĢ®, Ēæ£ņżĆĒÄĖņ░©, ņśżņ”łļ╣ä, ņ£äĒŚśļÅä ļō▒)ļ¦ī ņłśņÜöņ×ÉņŚÉĻ▓ī ĒÜīņŗĀĒĢśļŖö ļ░®ņŗØņØ┤ļŗż. ņłśņÜöņ×ÉļŖö ĒÅÉņćäļ¦Ø ņĢłņŚÉ ņ׳ļŖö ĒÖśņ×ÉņØś Ļ░£ļ│ä ņĀĢļ│┤ļź╝ ļ│┤Ļ▒░ļéś ņĘ©ļōØĒĢĀ ņłś ņŚåņ¦Ćļ¦ī, ņĀäņ▓┤ ļŹ░ņØ┤Ēä░ļź╝ ļ¬©ņĢäņä£ ļČäņäØĒĢ£ Ļ▓āĻ│╝ ļÅÖņØ╝ĒĢ£ ļČäņäØ Ļ▓░Ļ│╝ļź╝ ļÅäņČ£ĒĢĀ ņłś ņ׳ļŗż(Fig. 1). ļŗżļ¦ī ņØ┤ļź╝ ņ£äĒĢ┤ņä£ļŖö Ļ░ü ļ│æņøÉņØś ņĀĢĒśĢĒÖöļÉ£ ņĀäņ▓┤ ņ×äņāü ļŹ░ņØ┤Ēä░ļź╝ CDMņØä ņØ┤ņÜ®ĒĢśņŚ¼ ĒśĢņŗØĻ│╝ ņØśļ»Ėļź╝ Ēæ£ņżĆĒÖöĒĢśņŚ¼ņĢ╝ ĒĢ£ļŗż.
OHDSI
Observational Health Data Sciences and Informatics (ļśÉļŖö "Odyssey"ļØ╝Ļ│Ā ļ░£ņØīļÉśļŖö OHDSI)ļŖö 2008ļģäņŚÉ ļ»ĖĻĄŁ ņĀĢļČĆņØś ņ¦ĆņøÉņ£╝ļĪ£ Ļ▓░ņä▒ļÉ£ Observational Medical Outcomes Partnership (OMOP)ņ£╝ļĪ£ļČĆĒä░ ĒīīņāØļÉ£ ĻĄŁņĀ£ņĀü ĒśæņØśņ▓┤ņØ┤ļŗż. ņ┤łĻĖ░ņŚÉļŖö Ļ┤Ćņ░░ ņŚ░ĻĄ¼ ļ░®ļ▓ĢļĪĀĻ│╝ ļŹ░ņØ┤Ēä░ļź╝ ĒÖ£ņÜ®ĒĢśĻĖ░ ņ£äĒĢ£ ļČäņäØ ļÅäĻĄ¼ ļ░Å ņŗ£Ļ░üĒÖö ļÅäĻĄ¼, ĻĘĖļ”¼Ļ│Ā Ļ░ü ĻĖ░Ļ┤Ćļ¦łļŗż ļŗżļźĖ ņ¦äļŗ©, ņ▓śļ░® ņÜ®ņ¢┤ļź╝ ĒåĄņØ╝ĒĢ£ Ēæ£ņżĆ ņÜ®ņ¢┤ļź╝ ļ¦īļōżņŚłļŗż. OMOPļŖö 2013ļģä ņĀĢļČĆņØś ņ¦ĆņøÉņØ┤ ņśłņĀĢļīĆļĪ£ ņóģļŻīļÉ£ Ēøä, ņ░ĖņŚ¼ ņŚ░ĻĄ¼ņ×ÉļōżņØ┤ OHDSIļØ╝ļŖö ņØ┤ļ”äņ£╝ļĪ£ ņ×Éļ░£ņĀüņ£╝ļĪ£ Ļ▓░ņä▒ĒĢ£ ļ╣äņśüļ”¼ ĻĄŁņĀ£ ņŚ░ĻĄ¼ļŗ©ņ▓┤ņØ┤ļ®░ ņżæņĢÖņĪ░ņĀĢņä╝Ēä░ļŖö Columbia UniversityņŚÉ ņ£äņ╣śĒĢśĻ│Ā ņ׳ļŗż. OMOP-CDMĻ│╝ Ēæ£ņżĆ ņÜ®ņ¢┤ ņĀĢņØś ļō▒ņØä ņØ┤Ļ┤ĆĒĢśņŚ¼ Ļ│äņåŹ ļ░£ņĀäņŗ£ĒéżĻ│Ā ņ׳ļŗż. ĒŖ╣Ē׳ OMOP ņŗ£ņĀłņŚÉļŖö ņĢĮļ¼╝ ļČĆņ×æņÜ® ņĪ░ņé¼ ļ░®ļ▓ĢļĪĀņŚÉ ņ┤łņĀÉņØä ļ¦×ņČöņŚłņ¦Ćļ¦ī, OHDSIļĪ£ ņØ┤Ļ┤ĆĒĢ£ ņØ┤ĒøäņŚÉļŖö ņĢĮļ¼╝ņØś ņĢłņĀäņä▒, ļ╣äĻĄÉĒÜ©Ļ│╝ ņŚ░ĻĄ¼, Ļ▓ĮņĀ£ņä▒ ļČäņäØ, ņØśļŻīņØś ņ¦ł, ņØĖĻ│Ąņ¦ĆļŖź ĻĖ░ļ░śņØś ĒÖśņ×É Ļ░£ļ│ä ņ£äĒŚśļÅä ņśłņĖĪ ļō▒ ņ×äņāü ļ╣ģļŹ░ņØ┤Ēä░ ļČäņäØņ£╝ļĪ£ ņ¦äĒÖöĒĢ┤ ļéśĻ░ĆĻ│Ā ņ׳ļŗż.
OHDSI (https://www.ohdsi.org/)ņØś ļ¬©ļōĀ ņåöļŻ©ņģśņØĆ Git HubņŚÉ ņśżĒöł ņåīņŖżļĪ£ ņĀ£Ļ│ĄļÉśļ®░(https://github.com/ohdsi), OHDSI ņŚ░ĻĄ¼ ņ╗żļ«żļŗłĒŗ░(http://forums.ohdsi.org/)ļŖö ņŚ¼ļ¤¼ ļČäņĢ╝(ņ×äņāü ņØśĒĢÖ, ņāØļ¼╝ ĒåĄĻ│äĒĢÖ, ņ╗┤Ēō©Ēä░ Ļ│╝ĒĢÖ, ņŚŁĒĢÖ, ņāØļ¬ģ Ļ│╝ĒĢÖ)ņŚÉ Ļ▒Ėņ│É ņŚ░ĻĄ¼ņ×ÉļōżņØś ņĀüĻĘ╣ņĀüņØĖ ņ░ĖņŚ¼ļź╝ Ļ░ĆļŖźĒĢśĻ▓ī ĒĢśĻ│Ā ņ׳Ļ│Ā, ļŗżņ¢æĒĢ£ ņØ┤ĒĢ┤ Ļ┤ĆĻ│äņ×É ĻĘĖļŻ╣(ņśł: ņŚ░ĻĄ¼ņøÉ, ĒÖśņ×É, ņĀ£Ļ│Ąņ×É, ņ¦ĆļČłņ×É, ņĀ£ĒÆł ņĀ£ņĪ░ņŚģņ▓┤, ĻĘ£ņĀ£ ĻĖ░Ļ┤Ć)ņØä ĒżĻ┤äĒĢśĻ│Ā ņ׳ļŗż.
OHDSI ĒöäļĪ£ņĀØĒŖĖļŖö ĒśæņŚģ ĻĄ¼ņä▒ņøÉņØ┤ ņŻ╝ļÅäĒĢśĻ│Ā ļ”¼ļŹöņŗŁņØĆ ĒöäļĪ£ņĀØĒŖĖļ│äļĪ£ Ļ▓░ņĀĢļÉ£ļŗż. ļŹ░ņØ┤Ēä░ Ēæ£ņżĆĒÖö, ņĢłņĀä Ļ░Éņŗ£(safety surveillance), ļ╣äĻĄÉ ĒÜ©Ļ│╝ ņŚ░ĻĄ¼, ņØĖĻĄ¼ĒĢÖņĀü ĒÅēĻ░Ć, Ļ░£ņØĖ ļ¦×ņČżĒśĢ ņ£äĒŚś ņśłņĖĪ, ļŹ░ņØ┤Ēä░ ĒŖ╣ņä▒ ļČäņäØ, ĒÆłņ¦ł Ļ░£ņäĀ, ņ¦Ćļ”¼ņĀĢļ│┤ ļō▒ ļ╣ģļŹ░ņØ┤Ēä░ ĻĖ░ļ░śņØś Ļ▒░ņØś ļ¬©ļōĀ Ļ┤Ćņ░░ ņŚ░ĻĄ¼ ņśüņŚŁņŚÉ ņ┤łņĀÉņØä ļ¦×ņČöĻ│Ā ļŗżņ¢æĒĢ£ ņŚ░ĻĄ¼Ļ░Ć ņ¦äĒ¢ēļÉśĻ│Ā ņ׳ļŗż(https://github.com/OHDSI/StudyProtocolSandbox). OHDSIņØś ļ¬®Ēæ£ļŖö Ļ▒┤Ļ░ĢņØä Ē¢źņāüņŗ£ĒéżĻĖ░ ņ£äĒĢśņŚ¼ ņ¦ĆņŚŁ ņé¼ĒÜīĻ░Ć ĒśæļĀźĒĢśņŚ¼ ļ│┤ļŗż ļéśņØĆ Ļ▓░ņĀĢĻ│╝ ļ│┤ņé┤ĒĢīņØä ņ┤ēņ¦äĒĢśļŖö ņ”ØĻ▒░ļź╝ ņāØņä▒ĒĢĀ ņłś ņ׳ļÅäļĪØ ĻČīĒĢ£ņØä ļČĆņŚ¼ĒĢśļŖö Ļ▓āņØ┤ļŗż[2].
CDM
OHDSIĻ░Ć Ļ░£ļ░£ĒĢ£ OMOP-CDMņØĆ ņ¦ĆĻĖłĻ╣īņ¦Ć Ļ░£ļ░£ļÉ£ CDM ņżæ ņ×äņāü ņĀĢļ│┤ļź╝ Ļ░Ćņן Ļ┤æļ▓öņ£äĒĢśĻ▓ī ĒżĒĢ©ĒĢĀ ņłś ņ׳ļŖö ļŹ░ņØ┤Ēä░ ĻĄ¼ņĪ░ļź╝ Ļ░Ćņ¦ĆļÅäļĪØ ņäżĻ│äļÉśņ¢┤ ņ¦äĒÖöĒĢśĻ│Ā ņ׳ļŗż. OMOP-CDMņØĆ ņä£ļĪ£ ļŗżļźĖ Ļ┤ĆņĖĪ ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖżņØ╝ņ¦ĆļØ╝ļÅä ņ▓┤Ļ│äņĀüņØĖ ļČäņäØņØ┤ Ļ░ĆļŖźĒĢśļÅäļĪØ ņäżĻ│äļÉśņŚłļŗż. ņØ┤Ļ▓āņØ┤ Ļ░ĆļŖźĒĢ£ ņØ┤ņ£ĀļŖö ņä£ļĪ£ ļŗżļźĖ ļŹ░ņØ┤Ēä░ļ▓ĀņØ┤ņŖżņŚÉ ĒżĒĢ©ļÉ£ ļŹ░ņØ┤Ēä░ļź╝ Ēæ£ņżĆņĀüņØĖ Ļ│ĄĒåĄ Ēæ£Ēśä(ņÜ®ņ¢┤, ņ¢┤Ē£ś, ņĮöļō£ ņ▓┤Ļ│ä)ņ£╝ļĪ£ ļ│ĆĒÖśĒĢ£ ļŗżņØī, ļŹ░ņØ┤Ēä░ņØś ĻĄ¼ņĪ░ ļśÉĒĢ£ Ļ│ĄĒåĄ ĒśĢņŗØ (ļŹ░ņØ┤Ēä░ ļ¬©ļŹĖ)ņ£╝ļĪ£ ļ│ĆĒÖśĒĢśņŚ¼, Ļ│ĄĒåĄ ĒśĢņŗØņØä ĻĖ░ļ░śņ£╝ļĪ£ ņ×æņä▒ļÉ£ Ēæ£ņżĆ ļČäņäØ ļŻ©Ēŗ┤ ļØ╝ņØ┤ļĖīļ¤¼ļ”¼ļź╝ ņé¼ņÜ®ĒĢśņŚ¼ ņ▓┤Ļ│äņĀüņØĖ ļČäņäØņØä ņłśĒ¢ēĒĢśĻĖ░ ļĢīļ¼ĖņØ┤ļŗż.
OMOP CDMņØĆ v6.0 ĻĖ░ņżĆ ņ┤Ø 41Ļ░£ ĒģīņØ┤ļĖöļĪ£ ņØ┤ļŻ©ņ¢┤ņĀĖ ņ׳ņ£╝ļ®░, ņ×äņāü ņĀĢļ│┤ļź╝ ļŗ┤ļŗ╣ĒĢśļŖö clinical data, ņ×äņāü ņĀĢļ│┤ļĪ£ļČĆĒä░ ĒīīņāØļÉśļŖö derived elements, ĻĖ░Ļ┤ĆņØś ņĀĢļ│┤ļź╝ ļŗ┤Ļ│Ā ņ׳ļŖö health system data, ļ╣äņÜ® Ļ┤ĆļĀ© ļŹ░ņØ┤Ēä░ļź╝ ļŗ┤ļŗ╣ĒĢśļŖö health economics, Ēæ£ņżĆ ņÜ®ņ¢┤ļź╝ ĒåĄņ╣ŁĒĢśļŖö vocabulary, CDMņØś ļ®öĒāĆ ņĀĢļ│┤ļź╝ ļŗ┤Ļ│Ā ņ׳ļŖö meta-dataļĪ£ ĻĄ¼ļČäĒĢśņŚ¼ ņĀĢņØśĒĢśĻ│Ā ņ׳ļŗż(https://github.com/OHDSI/CommonDataModel/wiki). OHDSIņØś ņŚ░ĻĄ¼ņ×ÉļōżņØĆ OMOP CDMņØś ļ░£ņĀäĻ│╝ CDMņ£╝ļĪ£ņŹ©ņØś ņĀüņÜ®ņØä ņ£äĒĢśņŚ¼ ļģĖļĀźĒĢśĻ│Ā ņ׳ļŖöļŹ░, ĒŖ╣Ē׳ OHDSIņØś ņŚ¼ļ¤¼ ĒÖ£ļÅÖņĀüņØĖ ņ╗żļ«żļŗłĒŗ░ļōżņØĆ CDM ļ│ĆĒÖś, ņ£Āņ¦Ć ļ│┤ņłś ļō▒ņØä ņ£äĒĢśņŚ¼ ņä£ļĪ£ ĒśæļĀźĒĢśĻ│Ā ņ׳ļŗż.
Ēæ£ņżĆ ņÜ®ņ¢┤
CDMņØĆ ļŹ░ņØ┤Ēä░ ĻĄ¼ņĪ░ļŖö ļ¼╝ļĪĀ ņØśļ»ĖņØś Ēæ£ņżĆĒÖöļź╝ ņČöĻĄ¼ĒĢ£ļŗż. Ēśäņ×¼ OMOP Ēæ£ņżĆ ņÜ®ņ¢┤ņŚÉņä£ļŖö ņĢĮ 60ņŚ¼ ņóģļźś ņØ┤ņāüņØś ĻĄŁņĀ£Ēæ£ņżĆ ņÜ®ņ¢┤ļōżņØ┤ 300ļ¦ī Ļ░£ ņØ┤ņāü ĒżĒĢ©ļÉśņ¢┤ ņ׳ņ£╝ļ®░ Ļ░ü Ēæ£ņżĆ ņÜ®ņ¢┤ļōżņØĆ ņØśļ»ĖļĪĀņĀüņ£╝ļĪ£ ņāü┬ĘĒĢśņ£ä Ļ┤ĆĻ│äļź╝ ņØ┤ļŻ©ļ®░ ĻĄ¼ņä▒ļÉśņ¢┤ ņ׳ļŗż. ĒĢśņ¦Ćļ¦ī ĻĄŁņĀ£Ēæ£ņżĆ ņÜ®ņ¢┤Ļ░Ć ņĪ┤ņ×¼ĒĢśļŹöļØ╝ļÅä Ļ░ü ņØśļŻīĻĖ░Ļ┤ĆņØ┤ ĻĘĖ ĻĄŁņĀ£Ēæ£ņżĆ ņÜ®ņ¢┤ļź╝ ņé¼ņÜ®ĒĢśņ¦Ć ņĢŖĻ▒░ļéś ļČĆļČäņĀüņ£╝ļĪ£ļ¦ī ņé¼ņÜ®ĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ, Ļ░ü ļ│æņøÉņØś ļŹ░ņØ┤Ēä░ļź╝ ņĪ░ņé¼ĒĢśņŚ¼ ļ╣äĒæ£ņżĆ ņÜ®ņ¢┤ļź╝ Ēæ£ņżĆ ņÜ®ņ¢┤ļĪ£ ļ│ĆĒÖśĒĢśĻĖ░ ņ£äĒĢ£ ņÜ®ņ¢┤ ļ¦żĒĢæ ņ×æņŚģņØ┤ ĒĢäņÜöĒĢśļŗż. OHDSIņŚÉņä£ļŖö ņ¦ĆņåŹņĀüņØĖ OMOP ņÜ®ņ¢┤ņØś ņŚģļŹ░ņØ┤ĒŖĖļź╝ ņ¦äĒ¢ēĒĢśĻ│Ā ņ׳ņ£╝ļ®░, ņŚģļŹ░ņØ┤ĒŖĖņŚÉ ļö░ļØ╝ OMOP Ēæ£ņżĆ ņÜ®ņ¢┤Ļ░Ć ļ╣äĒæ£ņżĆ ņÜ®ņ¢┤ļĪ£ ļ│ĆĻ▓ĮļÉśĻ▒░ļéś ņÜ®ņ¢┤ļōż Ļ░äņØś ņāłļĪ£ņÜ┤ Ļ┤ĆĻ│äĻ░Ć ņĀĢņØśļÉśĻĖ░ļÅä ĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ņŚģļŹ░ņØ┤ĒŖĖ ļé┤ņÜ®ņØä ĒīīņĢģĒĢśņŚ¼ ņÜ®ņ¢┤ļōżņØś ļ¦żĒĢæ ņ×æņŚģņØä ņŻ╝ĻĖ░ņĀüņ£╝ļĪ£ ņłśĒ¢ē ļ░Å Ļ┤Ćļ”¼ĒĢśņŚ¼ņĢ╝ ĒĢ£ļŗż.
ļČäņäØĒł┤
OHDSIļŖö ļŗżņ¢æĒĢ£ ļŹ░ņØ┤Ēä░ ņäĖĒŖĖļź╝ CDMņ£╝ļĪ£ ļ│ĆĒÖśĒĢĀ ņłś ņ׳ļŖö ņ×ÉņøÉļōżņØä ņĀ£Ļ│ĄĒĢĀ ļ┐Éļ¦ī ņĢäļŗłļØ╝ ļ│ĆĒÖśļÉ£ CDMņØś Ļ░üņóģ ĒŖ╣ņ¦ĢņØ┤ļéś ĒåĄĻ│äĻ░ÆņØä ļ│┤ņŚ¼ņŻ╝ļŖö Achilles, Ēæ£ņżĆ ņÜ®ņ¢┤ Ļ▓ĆņāēĒł┤ņØĖ Athena, ņĮöĒśĖĒŖĖ ņČöņČ£, ņ£Āļ│æļźĀ Ļ│äņé░, ņä▒Ē¢źņĀÉņłśļ¦żņ╣Ł, ĻĖ░ņłĀ ļČäņäØ, ļŗ©ļ│Ćļ¤ē/ļŗżļ│Ćļ¤ē ļČäņäØ, ĻĖ░Ļ│äĒĢÖņŖĄĻĖ░ļ░ś ņśłņĖĪļ¬©ĒśĢ ĻĄ¼ņČĢ ļō▒ ĒåĄĒĢ® ļČäņäØĒł┤ņØĖ Atlas, ĻĖ░Ļ┤Ć Ļ░ä Ļ│ĄļÅÖ ņŚ░ĻĄ¼ļź╝ ņ£äĒĢ£ ArachneļØ╝ļŖö Ēł┤ ļō▒ 100ņóģ ņØ┤ņāüņØś ļŗżņ¢æĒĢ£ ļÅäĻĄ¼ļōżņØä ņĀ£Ļ│ĄĒĢ£ļŗż. OHDSIņØś ņśżĒöł ņåīņŖż ņåīĒöäĒŖĖņø©ņ¢┤ļŖö Git Hub ņĀĆņןņåīņŚÉņä£ ļ¼┤ļŻīļĪ£ ņé¼ņÜ®ĒĢĀ ņłś ņ׳ļŗż (https://GitHub.com/OHDSI/). ĻĄŁļé┤ņŚÉņä£ļŖö ņĢäņŻ╝ļīĆĒĢÖĻĄÉ ņØśļŻīņĀĢļ│┤ĒĢÖĻ│╝ņŚÉņä£ CDM ĻĖ░ļ░ś ņĢĮ 30ņóģ ņØ┤ņāüņØś ņśżĒöł ņåīņŖż ĒöäļĪ£ĻĘĖļשĻ│╝ ņŚ░ĻĄ¼ ĒöäļĪ£ĒåĀņĮ£ņØä Ļ░£ļ░£ĒĢśņŚ¼ Ļ│ĄĻ░£ĒĢśĻ│Ā ņ׳ļŗż(https://GitHub.com/abmi).
ņŚ░ĻĄ¼ ņ×¼Ēśäņä▒
OHDSIņØś Ļ░Ćņן Ēü░ ĒŖ╣ņ¦Ģ ņżæ ĒĢśļéśļŖö CDM ĻĖ░ļ░śņØś ņ×¼Ēśä Ļ░ĆļŖźĒĢ£ ņŚ░ĻĄ¼(reproducible research)ļź╝ ņČöĻĄ¼ĒĢ£ļŗżļŖö ņĀÉņØ┤ļŗż. ņĄ£ĻĘ╝ ļ╣ģļŹ░ņØ┤Ēä░ ņ£ĀĒ¢ēņŚÉ ņśüĒĢ®ĒĢśņŚ¼ ļ¦ÄņØĆ ņ×äņāü ņŚ░ĻĄ¼ļōżņØ┤ ņ£äņ¢æņä▒ ņ”ØĻ▒░(false-positive evidence)ļź╝ ņ¢æņé░ĒĢśĻ│Ā ņ׳ļŖö Ļ▓āņØ┤ ņĢäļŗīĻ░Ć ĒĢśļŖö ņÜ░ļĀżĻ░Ć ņ×ćļö░ļź┤Ļ│Ā ņ׳ļŗż. ņŗżņĀ£ļĪ£ PLOS MedicineņŚÉ ņŗżļ”░ ļģ╝ļ¼ĖņŚÉ ļö░ļź┤ļ®┤ ņŚ░ĻĄ¼ ļīĆņāüņ×É ņłśĻ░Ć ņČ®ļČäņ╣ś ņĢŖņØĆ ņŚŁĒĢÖ ņŚ░ĻĄ¼ņØś Ļ▓ĮņÜ░ 1/10 Ļ▓ĮņÜ░ļ¦īņØ┤ ļ»┐ņØä ņłś ņ׳Ļ│Ā, ļģ╝ļ¼ĖņØä ņ£äĒĢ£ ļģ╝ļ¼Ė(discovery-oriented exploratory research with massive testing)ņØś Ļ▓ĮņÜ░ 1,000Ļ░£ ņżæ 1Ļ░£ļ¦īņØ┤ ļ»┐ņØäļ¦īĒĢśļŗżĻ│Ā ĒĢ£ļŗż[3]. ņŚ░ĻĄ¼ ņ×¼Ēśäņä▒ņØä Ļ░ĆļĪ£ļ¦ēļŖö Ļ▓āņ£╝ļĪ£ļŖö ļŗżņØīņØś 4Ļ░Ćņ¦ĆĻ░Ć ņŻ╝ņÜö ņÜöņØĖņ£╝ļĪ£ Ļ╝ĮĒ×īļŗż[4]: ņČ®ļČäņ╣ś ņĢŖņØĆ ņŚ░ĻĄ¼ ļīĆņāüņ×É ņłś ļśÉļŖö ļé«ņØĆ ņ£äĒŚśļÅä ļ╣ä(low statistical power), ņČ£ĒīÉ ĒÄĖĒ¢ź(publication bias), pĻ░Æ ĒĢ┤Ēé╣(p-value hacking), Ļ▓░Ļ│╝ļź╝ ņĢīĻ│Āļé£ Ēøä Ļ░Ćņäż ņ×¼ņłśļ”Į HARKing (hypothesizing after results are known).
OHDSIļŖö p-value hacking ļ░Å HARKingņØä ļ░®ņ¦ĆĒĢśĻĖ░ ņ£äĒĢśņŚ¼ Ēł¼ļ¬ģņä▒(transparency), ņé¼ņĀä ņĀĢņØś(prespecify), ļČäņäØ Ļ▓Ćņ”Ø(validaiton of anlaysis)ņØś 3Ļ░Ćņ¦Ć ņŚ░ĻĄ¼ ņØ╝ļ░ś ņøÉņ╣ÖņØä ĻČīĻ│ĀĒĢśĻ│Ā ņ׳ļŗż. Ēł¼ļ¬ģņä▒Ļ│╝ ņé¼ņĀä ņĀĢņØśļź╝ ņ£äĒĢśņŚ¼ ļ¬©ļōĀ ņŚ░ĻĄ¼ ĒöäļĪ£ĒåĀņĮ£ ļ░Å ļČäņäØ ņĮöļō£ļōżņØĆ Git Hubļź╝ ĒåĄĒĢśņŚ¼ ņé¼ņĀäņŚÉ Ļ│ĄĻ░£ĒĢśļŖö Ļ▓āņØä ņøÉņ╣Öņ£╝ļĪ£ ĒĢ£ļŗż. ņŚ░ĻĄ¼ļź╝ ņ¦äĒ¢ēĒĢśĻĖ░ ņ£äĒĢ£ ņĀäņ▓┤ ĒīīņØ┤ĒöäļØ╝ņØĖņØä ļ©╝ņĀĆ ņäżĻ│äĒĢśĻ│Ā Ļ│ĄĻ░£ĒĢ©ņ£╝ļĪ£ņŹ©, ņ×¼Ēśäņä▒ņØä ļåÆņØ┤Ļ│Ā Ēł¼ļ¬ģņä▒ņØä ņĀ£Ļ│ĀĒĢĀ ņłś ņ׳ļŗż. Ļ│ĄĻ░£ļÉ£ ņĮöļō£ļōżņØĆ ņĀä ņäĖĻ│ä ņŚ░ĻĄ¼ņ×ÉļōżņŚÉ ņØśĒĢśņŚ¼ ņŗĀļó░ņä▒ņØä Ļ▓ĆĒåĀ ļ░øņØä ņłś ņ׳ļŗż. ļśÉĒĢ£ ļ»Ėļ”¼ ņ¦ĆņĀĢĒĢ£ 100ņŚ¼ Ļ░Ćņ¦ĆņØś ņØīņä▒ ļīĆņĪ░ĻĄ░ (negative control)ņØä ņŚ░ĻĄ¼ņ×ÉĻ░Ć ņĀĢņØśĒĢ£ ļČäņäØ ĒöäļĪ£ĒåĀņĮ£ļĪ£ ļÅÖņŗ£ņŚÉ ļČäņäØĒĢśļŖö ņ£äņ”Ø Ļ▓Ćņ”Ø(falsification test)ņØä ņłśĒ¢ēĒĢśĻĖ░ļź╝ ĻČīĒĢśĻ│Ā ņ׳ļŗż. ņØ┤ļŖö ļÅģļ”Įļ│ĆņłśņÖĆ ņĀäĒśĆ ņāüĻ┤ĆņŚåļŖö Ļ▓░Ļ│╝ Ļ░äņØś ņāüĻ┤ĆĻ┤ĆĻ│äĻ░Ć ņĀĢļ¦ÉļĪ£ ņ£ĀņØśļ»ĖĒĢśĻ▓ī ļéśņśżņ¦Ć ņĢŖļŖöņ¦Ćļź╝ Ļ▓Ćņ”ØĒĢśļŖö Ļ▓āņ£╝ļĪ£, ņśłļź╝ ļōżņ¢┤ ĒĢŁĒśłņåīĒīÉņĀ£ņĀ£ņØś ĒÜ©Ļ│╝ ļČäņäØ ņŚ░ĻĄ¼ņŚÉņä£ ļ»Ėļ”¼ ņĀĢņØśĒĢ£ ņØīņä▒ļīĆņĪ░ĻĄ░(ņśł: ļé┤Ē¢źņä▒ ņåÉĒå▒ņØś ļ░£ņāØ ļō▒)ņØ┤ ņāüĻ┤ĆĻ┤ĆĻ│äĻ░Ć ņĪ┤ņ×¼ĒĢśļŖö Ļ▓āņ£╝ļĪ£ Ļ▓░Ļ│╝Ļ░Ć ļéśņś©ļŗżļ®┤ ņØ┤ļŖö ņĀäņ▓┤ ļČäņäØ Ļ│╝ņĀĢņŚÉņä£ systemic errorļéś unmeasured confounderĻ░Ć ņĪ┤ņ×¼ĒĢśĻ▒░ļéś Ēś╣ņØĆ ņÜ░ņŚ░ņŚÉ ņØśĒĢ£ Ļ▓░Ļ│╝Ļ░Ć ņĪ┤ņ×¼ĒĢ©ņØä ņĢī ņłś ņ׳ļŗż.
ĻĄŁĻ░Ćļ│ä ļÅÖĒ¢ź
ļ»ĖĻĄŁņØĆ OMOP-CDMņØä Ļ░£ļ░£ĒĢśĻ│Ā OHDSIļź╝ ņŻ╝ļÅäĒĢśļŖö ĻĄŁĻ░ĆļĪ£ņŹ© ņĢĮ 200ņŚ¼ Ļ░£ ĻĖ░Ļ┤ĆņØ┤ ņ░ĖņŚ¼ĒĢśņŚ¼ ņ┤Ø 19ņ¢Ą ļ¬ģļČäņØś ņĀäņ×ÉņØśļ¼┤ĻĖ░ļĪØ(20%) ļ░Å ļ│┤ĒŚśņ▓ŁĻĄ¼ņ×ÉļŻī(80%)Ļ░Ć CDMņ£╝ļĪ£ ļ│ĆĒÖśļÉśņ¢┤ ņ׳ļŗż. National Institutes of Health, Food and Drug Administration (FDA), National Cancer Institute, eMERGEņŚÉņä£ OMOP-CDMņØä Ļ│ĄņŗØ ļŹ░ņØ┤Ēä░ ļ¬©ļŹĖ ņżæ ĒĢśļéśļĪ£ ņ▒äĒāØĒĢśĻ│Ā ņ׳ļŗż. 100ļ¦ī ļ¬ģļČäņØś ņ×äņāü ņĀĢļ│┤ņÖĆ ņ£ĀņĀäņ▓┤ ņĀĢļ│┤ļź╝ ļ¬©ņ£╝ļŖö All of Us ņŚ░ĻĄ¼ ĒöäļĪ£ĻĘĖļשņŚÉņä£ļÅä OMOP-CDMņØä Ļ│ĄņŗØ ļŹ░ņØ┤Ēä░ ļ¬©ļŹĖļĪ£ ņ▒äĒāØĒĢśĻ│Ā ņ׳ļŗż.
ņ£Āļ¤ĮņŚ░ĒĢ®ņØś ĒśüņŗĀņØśĒĢÖņØ┤ļŗłņģöĒŗ░ļĖī(Innovative Medicines Initiative, IMI)ļŖö ņ┤Ø 33ņ¢Ą ņ£ĀļĪ£ņØś ņśłņé░ņØä ļ│┤ņ£ĀĒĢ£ ņ£Āļ¤ĮņŚ░ĒĢ® ļ░Å ņ£Āļ¤ĮņĀ£ņĢĮ ņé░ņŚģĒśæĒÜīņÖĆņØś Ļ│ĄĻ│Ą-ļ»╝Ļ░ä ĒīīĒŖĖļäłņŗŁņ£╝ļĪ£ ļŗżņ¢æĒĢ£ ņŚ░ĻĄ¼ ĒöäļĪ£ņĀØĒŖĖņŚÉ ņŚ░ĻĄ¼ļ╣äļź╝ ņ¦ĆņøÉĒĢśĻ│Ā ņ׳ļŗż. IMI2ļŖö 2018ļģä 12ņøöņŚÉ European Health Data & Evidence Network (EHDEN) ĒöäļĪ£ņĀØĒŖĖļź╝ ņČ£ļ▓öĒĢśņśĆņ£╝ļ®░ Ē¢źĒøä 5ļģäĻ░ä ņ┤Ø 2,900ļ¦ī ņ£ĀļĪ£(372ņ¢Ą ņøÉ)ņØś ņŚ░ĻĄ¼ļ╣äļź╝ ņ¦ĆņøÉĒĢĀ ņśłņĀĢņØ┤ļŗż. EHDEN ĒöäļĪ£ņĀØĒŖĖļŖö ņ£Āļ¤Į 12Ļ░£ĻĄŁ 22Ļ░£ ņØ┤ņāüņØś ĻĖ░Ļ┤ĆļōżņØ┤ ļ│┤ņ£ĀĒĢ£ ņØśļŻīļŹ░ņØ┤Ēä░ļź╝ CDMņ£╝ļĪ£ ļ│ĆĒÖśĒĢśļŖö ĒöäļĪ£ņĀØĒŖĖļĪ£ņŹ© ņśźņŖżĒŹ╝ļō£ ļīĆĒĢÖ, Odysseus Data Services, ņ£Āļ¤ĮĒÖśņ×ÉņŚ░ĒĢ® ļō▒Ļ│╝ Ļ░ÖņØĆ ĻĖ░Ļ┤ĆņŚÉņä£ ņØĖņ”ØļÉ£ ņØśļŻī ļŹ░ņØ┤Ēä░ļź╝ ĒåĄĒĢ®ĒĢśņŚ¼ 1ņ¢Ąļ¬ģļČä ņØ┤ņāüņØś ĒÖśņ×É ļŹ░ņØ┤Ēä░ļź╝ ņØĄļ¬ģĒÖöĒĢśņŚ¼ Ļ│ĄĒåĄ ļŹ░ņØ┤Ēä░ļ¬©ļŹĖļĪ£ Ēæ£ņżĆĒÖöĒĢśļŖö Ļ▓āņØä ļ¬®Ēæ£ļĪ£ ĒĢśĻ│Ā ņ׳ļŗż. ĒÖĢļ│┤ļÉ£ ņŗżņĀ£ ņ×äņāü ļŹ░ņØ┤Ēä░ļź╝ ĒåĄĒĢśņŚ¼ ņ×äņāü ĻĘ╝Ļ▒░ļź╝ ņĀ£Ļ│ĄĒĢśņŚ¼ Ļ▒┤Ļ░Ģ, ņ¦łļ│æ, ņ╣śļŻīļ▓Ģ, ņśłĒøä ļ░Å ņāłļĪ£ņÜ┤ ņ╣śļŻīļ▓ĢņŚÉ ļīĆĒĢ£ ņŚ░ĻĄ¼ļź╝ ņłśĒ¢ēĒĢĀ Ļ│äĒÜŹņØ┤ļŗż. ļśÉĒĢ£ EHDEN ĒöäļĪ£ņĀØĒŖĖļŖö ļ»ĖĻĄŁņØ┤ ņŻ╝ļÅäĒĢśļŖö OHDSI ņé¼ņŚģ ļ░Å ĒĢ£ĻĄŁņØ┤ ņŻ╝ļÅäĒĢśļŖö ļČäņé░ĒśĢ ļ░öņØ┤ņśżĒŚ¼ņŖż ļ╣ģļŹ░ņØ┤Ēä░ Ēöīļ×½ĒÅ╝(FEEDER-NET)Ļ│╝ ĻĖ┤ļ░ĆĒ׳ ĒśæņŚģ ņżæņØ┤ļŗż.
ĒĢ£ĻĄŁņØś Ļ▓ĮņÜ░, OHDSI Korea (http://www.ohdsikorea.org)Ļ░Ć Ļ▓░ņä▒ļÉśņ¢┤ ĒÖ£ļÅÖ ņżæņØ┤ļ®░, ņé░ņŚģĒåĄņāüņ×ÉņøÉļČĆļŖö 2018ļģäļČĆĒä░ ĒŚ¼ņŖżņ╝Ćņ¢┤ ņé░ņŚģņØś ļ░£ņĀäĻ│╝ ĻĖĆļĪ£ļ▓ī Ļ▓Įņ¤üļĀź ĒÖĢļ│┤ļź╝ ņ£äĒĢśņŚ¼ CDM ĻĖ░ļ░ś ļČäņé░ĒśĢ ļ░öņØ┤ņśżĒŚ¼ņŖż ļ╣ģļŹ░ņØ┤Ēä░ Ēöīļ×½ĒÅ╝ ĻĄ¼ņČĢ ņé¼ņŚģņØä ņČöņ¦äĒĢśĻ│Ā ņ׳ļŗż(Fig. 2). ļ│Ė ņé¼ņŚģņŚÉņä£ļŖö ļ│æņøÉļōżņØś ņĀäņ×ÉņØśļ¼┤ĻĖ░ļĪØ ļŹ░ņØ┤Ēä░ļź╝ CDMņ£╝ļĪ£ ļ│ĆĒÖśĒĢśņŚ¼ ļ░öņØ┤ņśżĒŚ¼ņŖż ņ£ĄĒĢ® ļ╣ģļŹ░ņØ┤Ēä░ļ¦ØņØä ĻĄ¼ņČĢĒĢśĻ│Ā ņ£ĀņĀäņ▓┤, ņØśļŻīņśüņāü, ņāØņ▓┤ņŗĀĒśĖ ļō▒ ļŗżņ¢æĒĢ£ ļ╣äņĀĢĒśĢ ņØśļŻīļŹ░ņØ┤Ēä░ļź╝ ĒżĻ┤äĒĢĀ ņłś ņ׳ļŖö CDM ĒÖĢņן ļ¬©ļŹĖņØä Ļ░£ļ░£ĒĢśĻ│Ā ņ׳ļŗż. ļŹ░ņØ┤Ēä░ ņłśņÜöņ×ÉņÖĆ Ļ│ĄĻĖēņ×É ņŚ░Ļ│ä ļ░Å ļŗżĻĖ░Ļ┤Ć ļČäņäØ ĒöäļĪ£ņäĖņŖżļź╝ ņĮöļööļäżņØ┤ĒīģĒĢśļŖö FEEDER-NETņØ┤ļØ╝ ļ¬ģļ¬ģļÉ£ ņżæĻ│ä Ēöīļ×½ĒÅ╝ņØä Ļ░£ļ░£ĒĢśĻ│Ā ņ׳ņ£╝ļ®░, ļ│┤Ļ▒┤ņØśļŻī ņŚ░ĻĄ¼ņ×ÉļōżĻ│╝ Ļ┤ĆļĀ© ĻĖ░ņŚģļōżņØ┤ ņØ┤ Ēöīļ×½ĒÅ╝ņØä ņØ┤ņÜ®ĒĢśņŚ¼ ĒśüņŗĀņĀüņØĖ ņä£ļ╣äņŖżļź╝ Ļ░£ļ░£ĒĢśļÅäļĪØ ļÅĢĻ│Ā ņ׳ļŗż.
ļśÉĒĢ£ ņé░ņŚģĒåĄņāüņ×ÉņøÉļČĆļŖö 2019ļģäņŚÉ ļ░öņØ┤ņśżĒŚ¼ņŖż ļ╣ģļŹ░ņØ┤Ēä░ļ¦ØņØä ļ»Ėņ░ĖņŚ¼ ņāüĻĖēņóģĒĢ®ļ│æņøÉĻ│╝ ņóģĒĢ®ļ│æņøÉĻ╣īņ¦Ć ĒÖĢļīĆĒĢśļŖö ņé¼ņŚģņØä ņŗ£ņ×æĒĢśņśĆļŗż. ņØ┤ņŚÉ ļö░ļØ╝ ĻĖ░ņĪ┤ ņé¼ņŚģņŚÉ ļŹöĒĢśņŚ¼ ņ┤Ø 61Ļ░£ ļ│æņøÉļōżņØ┤ ņØ┤ ņé¼ņŚģņŚÉ ņ░ĖņŚ¼ĒĢśĻ▓ī ļÉśņŚłļŗż. ņŗĀĻĘ£ ņé¼ņŚģņŚÉņä£ļŖö ĻĖ░ņĪ┤ FEEDER-NETņØä Ļ│ĀļÅäĒÖöĒĢĀ ļČäņäØņ¦ĆņøÉ ļÅäĻĄ¼ ļ░Å ļŹ░ņØ┤Ēä░ ņ¦ł/ļ│┤ņĢł ĻĖ░ņłĀ Ļ░£ļ░£ ĒöäļĪ£ņĀØĒŖĖļŖö ļ¼╝ļĪĀ Ēöīļ×½ĒÅ╝ņØä ĒÖ£ņÜ®ĒĢ£ ĒśüņŗĀ ļ╣äņ”łļŗłņŖż ļ¬©ļŹĖ Ļ░£ļ░£ Ļ│╝ņĀ£ 4Ļ░£ļź╝ ņäĀņĀĢĒĢśņśĆļŗż. ļ╣äņ”łļŗłņŖż ļ¬©ļŹĖ Ļ░£ļ░£ Ļ│╝ņĀ£ņØś ņŻ╝ņĀ£ļŖö ļŗżņØīĻ│╝ Ļ░Öļŗż: ņ×äņāüņŗ£ĒŚś ņäżĻ│ä ņ¦ĆņøÉ ņä£ļ╣äņŖż; ļ│æņøÉ Ļ░ä ņ¦äļŻī ņ¦ĆņøÉ ņŗ£ņŖżĒģ£; ņ¦ĆļŖźĒśĢ ņ¦äļŗ©/ņ▓śļ░® ņĪ░ĒÜī ņä£ļ╣äņŖż; ļööņ¦ĆĒäĖ ļ░öņØ┤ņśżļ¦łņ╗ż Ļ░£ļ░£ Ļ│╝ņĀ£.
ņé░ņŚģĒåĄņāüņ×ÉņøÉļČĆļ┐É ņĢäļŗłļØ╝, ļ│┤Ļ▒┤ļ│Ąņ¦ĆļČĆņŚÉņä£ļÅä Ļ│╝ņĀ£ ļŗ╣ 3ļģäĻ░ä ņĢĮ 5ņ¢Ą ņøÉņØä ņ¦ĆņøÉĒĢśļŖö CDM ĒÖ£ņÜ®ņØä ĒåĄĒĢ£ ņØśĒĢÖ┬ĘņĀĢņ▒ģ┬ĘņØśļŻī ĻĖ░ņłĀ ļō▒ Ļ│ĄĻ│Ąļ¬®ņĀüņØś ņŚ░ĻĄ¼Ļ│╝ņĀ£ 12Ļ░£ļź╝ ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ņäĀņĀĢĒĢśņśĆļŗż: ļ│æļ”¼, ņŗ¼ņĀäļÅä, ņŗ¼ņ┤łņØīĒīī Ļ▓Ćņé¼ Ļ▓░Ļ│╝ ļ╣äņĀĢĒśĢļŹ░ņØ┤Ēä░ ĒÖĢņןļ¬©ļŹĖ Ļ░£ļ░£; ņ×äņāüņŗ£ĒŚś ĒÖĢņןļ¬©ļŹĖ; ņ×ÉĒĢ┤ ļ░Å ĒāĆĒĢ┤ Ē¢ēļÅÖ ņśłņĖĪņØä ņ£äĒĢ£ ņĀĢļ¤ēĒÖö ļ¬©ļŹĖ Ļ░£ļ░£; ņ£äņĢöĻ│╝ ļīĆņןņĢö ņśłļ░®ņØś ĒĢ£ĻĄŁĒśĢ ļ¦×ņČż ļ¬©ĒśĢ Ļ░£ļ░£; ļé┤ļČäļ╣ä ĒؼĻĘĆ ņ¦łĒÖś Ļ░£ļ░®ĒśĢ Ēöīļ×½ĒÅ╝ ĻĄ¼ņČĢ; Ļ░ÉņŚ╝ņä▒ ņ¦łĒÖś ļŹ░ņØ┤Ēä░ ĒÖĢņןļ¬©ļŹĖ Ļ░£ļ░£; ņŖżĒģīļĪ£ņØ┤ļō£ ņĢĮļ¼╝ ļČĆņ×æņÜ®ņØś ļČäņäØ Ēöīļ×½ĒÅ╝ Ļ░£ļ░£; ņØæĻĖē┬ĘņżæĒÖśņ×É ļīĆņāü ņĀĢļ░ĆņØśļŻī Ēöīļ×½ĒÅ╝ ĻĄ¼Ēśä; ņĢłņ¦łĒÖś CDM ĒÖĢņן Ēæ£ņżĆ ĻĖ░ļ░ś ļé£ņ╣śņä▒ ņŗżļ¬ģņ¦łĒÖśņØś ņ×äņāü ņ¢æņāü ļ░Å ļ╣äņÜ® ļČäņäØ ļäżĒŖĖņøīĒü¼ ņŚ░ĻĄ¼; ņØśļŻīļ░®ņé¼ņäĀ ļģĖņČ£ņØ┤ 2ņ░© ņĢö ļ░£ņāØņŚÉ ļ»Ėņ╣śļŖö ņśüĒ¢ź ņŚ░ĻĄ¼; ļŗ╣ļć©ļ│æ Ļ┤Ćļ”¼ ĒÜ©Ļ│╝ ļ░Å ļ╣äņÜ® ļČäņäØĻ│╝ Ļ░£ņäĀļ░®ņĢł. ļ│┤Ļ▒┤ļ│Ąņ¦ĆļČĆļŖö ļśÉĒĢ£ Ļ│ĄņØĄņĀü ļ¬®ņĀüņØś CDM ĒÖ£ņÜ®ņØä ņ£äĒĢ£ ņĀ£ļÅä ļ░Å ņĀĢļ│┤ļ│┤ĒśĖĻĖ░ņłĀ ņŚ░ĻĄ¼ļź╝ ļ¬®Ēæ£ļĪ£ 3ļģäĻ░ä ņĢĮ 5ņ¢Ą ņøÉņØä ņ¦ĆņøÉĒĢśļŖö 10Ļ░£ Ļ│╝ņĀ£ļź╝ ņäĀņĀĢĒĢśņśĆļŗż.
ļÅäņĀä
ņĀĢĒśĢ ņ×äņāüņ×ÉļŻī CDM Ēæ£ņżĆĒÖöņŚÉ ļ╣äĒĢśņŚ¼ ļ╣äņĀĢĒśĢ ņ×äņāüņ×ÉļŻīņØś ĒÖ£ņÜ® ļ░Å ņĀĢĒśĢ ņ×ÉļŻīņÖĆņØś ņ£ĄĒĢ®ņØĆ ņĢäņ¦ü ļ»Ėļ╣äĒĢśļŗż. ļ╣äņĀĢĒśĢ ļŹ░ņØ┤Ēä░ļ×Ć ļ»Ėļ”¼ ņĀĢņØśļÉ£ ļŹ░ņØ┤Ēä░ ļ¬©ļŹĖņØ┤ ņŚåĻ▒░ļéś ņĀĢļ”¼ļÉśņ¦Ć ņĢŖņØĆ ņĀĢļ│┤ļź╝ ļ£╗ĒĢ£ļŗż. ļ│æņøÉņŚÉņä£ ņāØņä▒ļÉśļŖö ļ╣äņĀĢĒśĢ ļŹ░ņØ┤Ēä░ļĪ£ļŖö ņØśņé¼Ļ░Ć ņ×Éņ£ĀļĪŁĻ▓ī ĻĖ░ņ×ģĒĢśļŖö ņ×Éņ£Āņ¦äņłĀļ¼Ė ĒśĢĒā£ņØś Ļ░üņóģ ņ¦äļŻī ĻĖ░ļĪØņØ┤ļéś Ļ▓Ćņé¼/ņŗ£ņłĀ ĻĖ░ļĪØņ¦Ć, ļ│æļ”¼ļéś ļ░®ņé¼ņäĀ ņśüņāü, ļé┤ņŗ£Ļ▓Į ņé¼ņ¦ä ļ░Å Ļ░üņóģ ļÅÖņśüņāü, ĒÖśņ×É Ļ░Éņŗ£ ņןņ╣śņŚÉņä£ ņāØņä▒ļÉśļŖö ņŗżņŗ£Ļ░ä ņāØņ▓┤ ņŗĀĒśĖ, ņ£ĀņĀäņ×É Ļ▓Ćņé¼ Ļ▓░Ļ│╝ ļō▒ņØä ļōż ņłś ņ׳ļŗż. ņØ┤ļōż ļ╣äņĀĢĒśĢ ļŹ░ņØ┤Ēä░ļŖö ņØśļŻīĻĖ░Ļ┤ĆņŚÉņä£ ļ░£ņāØĒĢśļŖö ļŹ░ņØ┤Ēä░ņØś 80% ņØ┤ņāüņØä ņ░©ņ¦ĆĒĢśņ¦Ćļ¦ī ļīĆļČĆļČä ņĀ£ļīĆļĪ£ ņłśņ¦æĒĢśņ¦Ć ņĢŖĻ▒░ļéś Ļ┤Ćļ”¼ļÉśņ¦Ć ņĢŖņĢä ļ▓äļĀżņ¦ĆĻ│Ā ņ׳ļŗż. ņĄ£ĻĘ╝ ĒĢ£ĻĄŁņØä ņżæņŗ¼ņ£╝ļĪ£ ņ£ĀņĀäņ▓┤ ļŹ░ņØ┤Ēä░ļź╝ ņ£äĒĢ£ Genomic CDM [5], ļ░®ņé¼ņäĀņśüņāü ļŹ░ņØ┤Ēä░ļź╝ ņ£äĒĢ£ Radiology CDM, ņØ┤ļōż ļŹ░ņØ┤Ēä░ļź╝ ļŗżļŻ░ ņłś ņ׳ļŖö ņ¢┤Ēöīļ”¼ņ╝ĆņØ┤ņģś ļō▒ CDM ĒÖĢņן ļ¬©ļŹĖĻ│╝ Ļ░üņóģ ņØæņÜ® ņåīĒöäĒŖĖņø©ņ¢┤ļź╝ ĒÖ£ļ░£Ē׳ Ļ░£ļ░£ĒĢśĻ│Ā ņ׳ļŖö ņĀÉņØĆ ļ¦żņÜ░ Ļ│Āļ¼┤ņĀüņØ┤ļØ╝ ĒĢĀ ņłś ņ׳ļŗż.
ļÅÖņØ╝ĒĢ£ ļŹ░ņØ┤Ēä░ ĻĄ¼ņĪ░ņŚÉ ļīĆĒĢśņŚ¼ ĒĢśļéśņØś ļČäņäØ ņĮöļō£ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ļČäņäØņØä ņ¦äĒ¢ēĒĢĀ Ļ▓ĮņÜ░, Ļ░ü ĻĖ░Ļ┤Ćļ│ä ļČäņäØņŚÉ Ļ▒Ėļ”¼ļŖö ņŗ£Ļ░ä ņ×Éņ▓┤ļŖö ļ╣äĻĄÉņĀü ņ¦¦ņØĆ ĒÄĖņØ┤ļŗż. ĒĢśņ¦Ćļ¦ī ĻĖ░Ļ┤Ćļ│äļĪ£ ņ£żļ”¼ņŗ¼ņØśņ£äņøÉĒÜīņØś ņŗ¼ņØśļź╝ ņÜöņ▓ŁĒĢśĻ│Ā ņŗ¼ņØśļź╝ ļ░øļŖö Ļ│╝ņĀĢņØĆ ļŗżĻĄŁņĀü┬ĘļŗżĻĖ░Ļ┤Ć Ļ│ĄļÅÖ ņŚ░ĻĄ¼ņØś Ļ░Ćņן Ēü░ ņןņĢĀļ¼╝ņØ┤ļŗż. Sentinel InitiativeņØś Ļ▓ĮņÜ░ FDAĻ░Ć ņÜöņ▓ŁņŚÉ ņØśĒĢ£ ļČäņäØņØś Ļ▓ĮņÜ░ Institutional Review Board (IRB) ņŗ¼ņØś ļśÉļŖö IRB ļ®┤ņĀ£ņŗ¼ņØś ņØ╝ņ▓┤Ļ░Ć ĒĢäņÜö ņŚåņØīņØä ņĀĢļČĆņŚÉņä£ Ļ│ĄĒæ£ĒĢśņśĆļŗż. Patient-Centered Outcomes Research Institute (PCORI)ņØś ĒøäņøÉņ£╝ļĪ£ ņäĖņøīņ¦ä Patient Outcome Research to Advance Learning (PORTAL) ļäżĒŖĖņøīĒü¼ņØś Ļ▓ĮņÜ░ ņŚ░ĻĄ¼ļ│äļĪ£ ņŚ░ĻĄ¼ļź╝ ņŻ╝ļÅäĒĢ£ ĻĖ░Ļ┤ĆņØś IRB ņŗ¼ņØśļź╝ ĒåĄĻ│╝ĒĢśļ®┤, ļéśļ©Ėņ¦Ć ĻĖ░Ļ┤ĆņØĆ ņŻ╝ļÅä ĻĖ░Ļ┤ĆņØś IRBņŚÉ Ļ░ÉļÅģĻČīņØä ņØ┤ņ¢æĒĢśļŖö ļ░®ņŗØņØä ņ▒äĒāØĒĢ£ļŗż. ĻĄŁļé┤ņŚÉņä£ļŖö ļČäņé░ ņŚ░ĻĄ¼ļ¦ØņŚÉ ļīĆĒĢ£ ņØ┤ĒĢ┤ ļ░Å ļģ╝ņØśĻ░Ć ņĢäņ¦ü ļČĆņĪ▒ĒĢ£ ņŗżņĀĢņ£╝ļĪ£ ļ¬ģĒÖĢĒĢ£ Ļ░ĆņØ┤ļō£ļØ╝ņØĖņØ┤ ņŚåļŗż. Ēśäņ×¼Ļ╣īņ¦ĆļŖö ļ¬©ļōĀ Ļ░£ļ│ä ņŚ░ĻĄ¼ņŚÉ ļīĆĒĢśņŚ¼ Ļ░ü ĻĖ░Ļ┤Ćļ│ä IRB ņŗ¼ņØśļź╝ ļ░øĻ│Ā ņ׳ņ¢┤, ņŚ░ĻĄ¼Ļ░Ć ņ¦ĆņŚ░ļÉśļŖö Ļ▓ĮņÜ░Ļ░Ć ļ¦Äļŗż. ņāØļ¬ģņ£żļ”¼ ļ░Å ņĢłņĀäņŚÉ Ļ┤ĆĒĢ£ ļ▓ĢļźĀ ņĀ£15ņĪ░(ņØĖĻ░äļīĆņāüņŚ░ĻĄ¼ņØś ņŗ¼ņØś)ņŚÉņä£ļŖö "ŌæĀ ņØĖĻ░äļīĆņāüņŚ░ĻĄ¼ļź╝ ĒĢśļĀżļŖö ņ×ÉļŖö ņØĖĻ░äļīĆņāüņŚ░ĻĄ¼ļź╝ ĒĢśĻĖ░ ņĀäņŚÉ ņŚ░ĻĄ¼Ļ│äĒÜŹņä£ļź╝ ņ×æņä▒ĒĢśņŚ¼ ĻĖ░Ļ┤Ćņ£äņøÉĒÜīņØś ņŗ¼ņØśļź╝ ļ░øņĢäņĢ╝ ĒĢ£ļŗż."ļĪ£ ĻĘ£ņĀĢĒĢśĻ│Ā ņ׳ņ£╝ļ®░, ņŗ£Ē¢ēĻĘ£ņ╣Ö ņĀ£2ņĪ░(ņØĖĻ░äļīĆņāüņŚ░ĻĄ¼ņØś ļ▓öņ£ä)ņŚÉņä£ļŖö "ņØĖĻ░äļīĆņāüņŚ░ĻĄ¼"ņØś ņĀĢņØśļĪ£ņŹ© ņé¼ļ×īņØä ļīĆņāüņ£╝ļĪ£ ļ¼╝ļ”¼ņĀüņ£╝ļĪ£ Ļ░£ņ×ģĒĢśļŖö ņŚ░ĻĄ¼, ņāüĒśĖņ×æņÜ®ņØä ĒåĄĒĢśņŚ¼ ņłśĒ¢ēĒĢśļŖö ņŚ░ĻĄ¼, Ļ░£ņØĖņØä ņŗØļ│äĒĢĀ ņłś ņ׳ļŖö ņĀĢļ│┤ļź╝ ņØ┤ņÜ®ĒĢśļŖö ņŚ░ĻĄ¼ļĪ£ ĻĘ£ņĀĢĒĢśĻ│Ā ņ׳ņ£╝ļ»ĆļĪ£, ņŚ░ĻĄ¼ņ×ÉĻ░Ć Ļ░Ćļ¬ģĒÖöļÉ£ CDM ļŹ░ņØ┤Ēä░ņŚÉ ņ¦üņĀæ ņĀæĻĘ╝ņØ┤ ļČłĻ░ĆĒĢśĻ│Ā ņØĄļ¬ģņØś ļČäņé░ļ¦ØņØä ĒåĄĒĢśņŚ¼ Ļ░äņĀæņĀüņ£╝ļĪ£ ļČäņäØ Ļ▓░Ļ│╝ļ¦ī ņ¢╗ļŖö Ļ│╝ņĀĢņØ┤ "ņØĖĻ░äļīĆņāüņŚ░ĻĄ¼"ņØś ĻĖ░ņżĆņŚÉ ĒĢ┤ļŗ╣ĒĢśļŖöņ¦Ć, ļö░ļØ╝ņä£ IRB ņŗ¼ņØśļéś ņŗ¼ņØśļ®┤ņĀ£ ņĀłņ░© ņ×Éņ▓┤Ļ░Ć ĒĢäņÜöĒĢ£ņ¦ĆņŚÉ ļīĆĒĢśņŚ¼ ņØśļ¼ĖņØ┤ ņĀ£ĻĖ░ļÉśĻ│Ā ņ׳ļŗż. ņØ╝ļČĆ ņ░ĖņŚ¼ ĻĖ░Ļ┤ĆņŚÉņä£ļŖö CDM ĻĖ░ļ░ś ļŗżĻĖ░Ļ┤Ć ņŚ░ĻĄ¼Ļ░Ć IRB ņŗ¼ņØśļéś ņŗ¼ņØśļ®┤ņĀ£ ņÜöĻ▒┤ņŚÉ ĒĢ┤ļŗ╣ĒĢśņ¦Ć ņĢŖļŖö Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ĒĢśņŚ¼, ĒāĆ ĻĖ░Ļ┤ĆņØś ņŻ╝ ņŚ░ĻĄ¼ņ×ÉĻ░Ć IRB ņŗ¼ņØśļź╝ ļ░øņØĆ Ļ▓ĮņÜ░ļĪ£ņŹ© ļŗ©ņł£Ē׳ ļČäņäØņĮöļō£ļź╝ ņŗżĒ¢ēļ¦ī ĒĢ┤ņŻ╝ļŖö Ļ▓ĮņÜ░ņŚÉļŖö ņČöĻ░ĆņĀüņØĖ IRB ņŗ¼ņØśļéś IRB ļ®┤ņĀ£ņŗ¼ņØśļź╝ ņÜöĻĄ¼ĒĢśņ¦Ć ņĢŖĻ│Ā ņ׳ļŗż.
Ļ▓░ ļĪĀ
OHDSI ņ╗©ņåīņŗ£ņŚäņŚÉ ņ×äņāü ļŹ░ņØ┤Ēä░ļź╝ Ļ░Ćņ¦ä ļ¦ÄņØĆ ĻĖ░Ļ┤ĆļōżņØ┤ ņ░ĖņŚ¼ĒĢśĻ│Ā ņ׳ņ£╝ļ®░, ļŗżņ¢æĒĢ£ ļČäņĢ╝ņØś ņŚ░ĻĄ¼ņ×ÉĻ░Ć ņ×Éļ░£ņĀüņ£╝ļĪ£ ņ░ĖņŚ¼ĒĢśņŚ¼ ļ¦ÄņØĆ ņØæņÜ® ņåīĒöäĒŖĖņø©ņ¢┤ņÖĆ ĒÖĢņן ļ¬©ļŹĖ, ļŗżņ¢æĒĢ£ ļČäņäØ ņŚ░ĻĄ¼ļź╝ ņłśĒ¢ēĒĢśļŖö ļō▒, ņĀä ņäĖĻ│äņĀüņ£╝ļĪ£ ĻĘĖ ĻĘ£ļ¬©Ļ░Ć ļ╣Āļź┤Ļ▓ī ĒÖĢņןļÉśĻ│Ā ņ׳ļŗż. ĻĄŁļé┤ņŚÉņä£ļÅä ļ▓öņĀĢļČĆņ░©ņøÉņØś ņ¦ĆņøÉņ£╝ļĪ£ CDM ņżæņŗ¼ņØś ļŗżņ¢æĒĢ£ ĻĖ░ņ┤ł ļ░Å ņØæņÜ® ņŚ░ĻĄ¼ ĒöäļĪ£ņĀØĒŖĖĻ░Ć ņ¦äĒ¢ēļÉśĻ│Ā ņ׳ļŗż.
CDM ĻĖ░ļ░śņØś ļČäņé░ņŚ░ĻĄ¼ļ¦ØņØĆ ļŹ░ņØ┤Ēä░ņØś ņåīņ£ĀņÖĆ ļČäņäØņØä ļČäļ”¼ĒĢ©ņ£╝ļĪ£ņŹ© ļŹ░ņØ┤Ēä░ļź╝ ņåīņ£ĀĒĢśņ¦Ć ņĢŖņ£╝ļ®┤ņä£ļÅä Ēł¼ļ¬ģĒĢśĻ│Ā ņ×¼Ēśä Ļ░ĆļŖźĒĢ£ ņ”ØĻ▒░ļź╝ ļ▓öņäĖĻ│äņĀü ĻĘ£ļ¬©ļĪ£ ņēĮĻ▓ī ņ¢╗ņØä ņłś ņ׳ļŖö ņŚ░ĻĄ¼ļ¦ØņØ┤ļŗż. ĻĖ░ņłĀ ļČäņäØņØ┤ļéś ņØĖĻ│╝ņä▒ ĒÅēĻ░ĆņÖĆ Ļ░ÖņØĆ ĒåĄĻ│äņĀü ĻĖ░ļ▓Ģļ┐É ņĢäļŗłļØ╝ ĻĖ░Ļ│äĒĢÖņŖĄ ĻĖ░ļ░śņØś ņØĖĻ│Ąņ¦ĆļŖź ņĢīĻ│Āļ”¼ļō¼ņØä ņØ┤ņÜ®ĒĢ£ ņśłņĖĪ ļ¬©ĒśĢļÅä ņēĮĻ▓ī ļ¦īļōż ņłś ņ׳ļŗż. RņØ┤ļéś ĒīīņØ┤ņŹ¼Ļ│╝ Ļ░ÖņØĆ ĒöäļĪ£ĻĘĖļשņØä ņØ┤ņÜ®ĒĢśņŚ¼ ļŹ░ņØ┤Ēä░ ņĀĢņĀ£ņŚÉņä£ļČĆĒä░ ļ│ĆĒÖś/ļČäņäØ/ņŗ£Ļ░üĒÖöĻ╣īņ¦Ć ņØ╝Ļ┤äņ▓śļ”¼Ļ░Ć Ļ░ĆļŖźĒĢśņŚ¼ ļ¦ÄņØĆ ņłśņØś ļīĆĻĘ£ļ¬© ļČäņäØņØä ļÅÖņŗ£ņŚÉ ņ¦äĒ¢ēĒĢĀ ņłś ņ׳ļŗż. ņØ╝Ļ░£ ĻĖ░Ļ┤ĆĻ│╝ ĻĄŁĻ░Ćļź╝ ļäśņ¢┤ņä£ ņĀä ņäĖĻ│ä ļ¦ÄņØĆ ĻĖ░Ļ┤ĆĻ│╝ņØś ņŚ░Ļ│äĻ░Ć Ļ░ĆļŖźĒĢśļ»ĆļĪ£ ņĀä ņäĖĻ│äņĀü ĻĘ£ļ¬©ņØś ĻĖ░Ļ┤Ć ļ░Å ĻĄŁĻ░Ć Ļ░ä ļ╣äĻĄÉ-ĒåĄĒĢ® ļČäņäØņØ┤ Ļ░ĆļŖźĒĢ£ ņןņĀÉņØ┤ ņ׳ļŗż.
ĒĢśņ¦Ćļ¦ī ņĢäņ¦ü ļ╣äņĀĢĒśĢ ļŹ░ņØ┤Ēä░ņŚÉ ļīĆĒĢ£ Ēæ£ņżĆĒÖö ĻĖ░ņłĀņØĆ ļŹö ļ¦ÄņØĆ ņ░ĖņŚ¼ņÖĆ Ļ░£ļ░£ņØ┤ ĒĢäņÜöĒĢ£ ņāüĒÖ®ņØ┤ļŗż. CDMņØä ĒÖ£ņÜ®ĒĢ£ ņŚ░ĻĄ¼ļ░®ļ▓ĢļĪĀņŚÉ ļé»ņäĀ ļ¦ÄņØĆ ņ×äņāü ņŚ░ĻĄ¼Ļ░ĆļōżņŚÉ ļīĆĒĢ£ ĻĄÉņ£Ī ĒöäļĪ£ĻĘĖļשļÅä ņŗ£ĻĖēĒ׳ ļ¦łļĀ©ļÉśņ¢┤ņĢ╝ ĒĢ£ļŗż. CDMņ£╝ļĪ£ ļ│ĆĒÖśĒĢ£ ļŹ░ņØ┤Ēä░ņŚÉ ļīĆĒĢ£ ņ¦ł ĒÅēĻ░Ć ļ░®ļ▓ĢļĪĀĻ│╝ ņ¦ł Ļ░£ņäĀ ļ░®ļ▓ĢļĪĀņØ┤ ņ¦ĆņåŹņĀüņ£╝ļĪ£ Ļ░£ļ░£ļÉśņ¢┤ņĢ╝ ĒĢ£ļŗż[6]. ĻĖ░ņĪ┤ņØś ņĀäĒåĄņĀüņØĖ IRB ņØĖņ”Øņ▓┤Ļ│äņŚÉņä£ ņÜöĻĄ¼ĒĢśļŖö ļČłĒĢäņÜöĒĢ£ ņĀłņ░© ļśÉĒĢ£ Ļ░£ņäĀļÉśņ¢┤ņĢ╝ ĒĢĀ ĒĢäņÜöņä▒ņØ┤ ņ׳ļŗż. ņØ┤ļ¤¼ĒĢ£ ĻĖ░ņŚ¼ņÖĆ ĒÄĖņØĄņØś ņĪ░ĒÖöĻ░Ć ņ¢æņł£ĒÖśņØä ņØ┤ļŻ©ĻĖ░ ņ£äĒĢ┤ņä£ļŖö ļČäņé░ņŚ░ĻĄ¼ļ¦Ø ņ░ĖņŚ¼ņ×Éļōż Ļ░äņŚÉ ņ×Éņ£ĀļĪŁĻ▓ī ņØśĻ▓¼ņØ┤ ņĀ£ņŗ£ļÉśĻ│Ā ļ»╝ņŻ╝ņĀüņ£╝ļĪ£ Ļ▓░Ļ│╝ļź╝ ļÅäņČ£ĒĢśļŖö Ļ▒░ļ▓äļäīņŖż ņ▓┤Ļ│äĻ░Ć ĻĄ¼ņČĢļÉśņ¢┤ņĢ╝ ĒĢśļ®░, ĻĖ░ņŚ¼ĒĢ£ ļ¦īĒü╝ Ēś£ĒāØņØä ļ░øļŖö ņāüĒśĖ ĒśĖĒś£ ĻĖ░ļ░śņØś ņĀĢļ¤ē ļ░Å ņĀĢņä▒ņĀü ņØĖņä╝Ēŗ░ļĖī ņĀ£ļÅäĻ░Ć ļ¦łļĀ©ļÉśņ¢┤ņĢ╝ ĒĢĀ Ļ▓āņØ┤ļŗż.
OHDSI ņ╗©ņåīņŗ£ņŚäņØĆ ņ¦ĆņŚŁļ│ä, ņŻ╝ņĀ£ļ│ä, ĻĖ░ņłĀļ│ä ņ×æņØĆ ļŗ©ņ£äņØś ņ╗żļ«żļŗłĒŗ░ļź╝ ņ¦ĆņøÉĒĢśĻ│Ā ņ׳ņ£╝ļ®░, ņØ┤ļ¤¼ĒĢ£ ņ╗żļ«żļŗłĒŗ░ļŖö OHDSI ņāØĒā£Ļ│äļź╝ ņ¦ĆņåŹĒĢśļŖö ĒלņØ┤ ļÉśĻ│Ā ņ׳ļŗż. Ļ░ü ņ╗żļ«żļŗłĒŗ░ļōżņØ┤ ĒśæļĀźņØä ĒåĄĒĢśņŚ¼ ļČäņé░ņŚ░ĻĄ¼ļ¦ØņØä ĒÖ£ņä▒ĒÖöņŗ£ĒéżĻ│Ā ļ░£ņĀäņŗ£ĒéżļŖö ņŗ£ļäłņ¦Ćļź╝ ļ░£Ē£śĒĢ£ļŗżļ®┤ OHDSI ņāØĒā£Ļ│äņØś ĻĖ░ļ░śņØĆ ļŹöņÜ▒ Ļ▓¼Ļ│ĀĒĢ┤ņ¦ł Ļ▓āņØ┤ļ®░ ņØśĒĢÖņĀü ļ░£ņĀäĻ│╝ ņØĖļźś ļ│┤Ļ▒┤ņŚÉ ĻĖ░ņŚ¼ĒĢĀ ņłś ņ׳Ļ▓ī ļÉĀ Ļ▓āņØ┤ļŗż.

 PDF Links
PDF Links PubReader
PubReader ePub Link
ePub Link Full text via DOI
Full text via DOI Download Citation
Download Citation Print
Print