건강보험 빅데이터를 이용한 임상 연구: 실제와 전망
Clinical Research from a Health Insurance Database: Practice and Perspective
Article information
Trans Abstract
Health insurance big data not only provide real-world evidence of unmet needs in actual clinical practice but also of breakthroughs in the medical industry which will shape the future of health care. Big data are also expected to transform the existing medical paradigm and provide a truly personalized medical age. However, questions about research through the collection and utilization of various big data in various fields have also been raised because quality limitations cannot be overlooked. Therefore, many challenges remain to be overcome in the use of big data research as a basis for changing medical practice. Intervention and interpretation by clinical medical experts are required in judging the scientific trustworthiness of the big data analysis process and the validity of the results. Therefore, healthcare big data research cannot achieve its goal by the efforts of researchers alone. Teams of data analysis scientists, epidemiologists, statistics experts, and clinical researchers are required to collaborate closely with team members, from the design phase to expert consultation, through regular meetings. In addition, it is necessary, in the creation of a healthier community, to cooperate with government agencies that provide data based on the whole nation or the world’s population, as well as interest groups representing the people, and policy-making organizations. In this paper, we describe the knowledge, practical clinical applications, and future research directions and prospects for the next phase of health care, from the design of clinical research using health insurance big data to report writing.
서 론
보건 의료(healthcare) 빅데이터는 단순히 방대한 양의 자료와 자료원이라기보다는 진료 정보 기반의 건강과 관련된 유전체, 가족 및 친구 관계, 생물학적 표현형, 환경 노출, 행동 및 생활 습관 등을 전부 포함하는 다양하고 복잡한 자료를 의미한다. 여기에는 병, 의원이 가진 자료 또는 국가 기관에서 제공하는 보험 청구 데이터가 포함된다. 대부분의 국내 인구 기반 빅데이터 임상 연구 결과는 후자에 기반하여 자격, 일반 건강검진, 암 검진 정보가 추가된 자료원으로 국민건강보험공단(이하 건보공단) 자료가 대표적이며 이 자료 체계는 건강보험 빅데이터로 정의될 수 있다[1].
요람에서 무덤까지 사회보장을 표방하는 북유럽 국가에서는 이미 반 세기 이상 건강보험 빅데이터가 축적되어 인구 기반의 주요 질환에 대한 건강보험 자료나 지속적인 국가 관리와 지원이 필요한 희귀난치병 등록 코호트 자료가 건강보험 제도의 틀 내에서 자연스럽게 구축되어왔다. 이를 통해 질병 예방, 진단, 치료 영역에서 인구 기반 임상 결과(clinical outcome)를 분석하고 국가 건강 정책을 수립하는 근거로 이용되고 있다. 가까운 대만에서도 장기 전략과 비전을 기반으로 건강보험 정책을 수립하여 일찍이 빅데이터 기반의 코호트 연구를 설계, 분석함으로써 최근 건강보험 빅데이터 연구에서 세계를 선도하고 있다. 이러한 건강보험 빅데이터는 실제 임상에서 미충족 수요에 대한 실 세계 근거(real world evidence)를 제공할 뿐만 아니라 보건 의료 분야의 미래를 선도할 4차 산업혁명의 핵심 마중물로써 부가가치를 인정받아 향후 의료 산업의 돌파구로 인식되고 있다.
국내에서도 건강보험 빅데이터 연구를 통하여 체계적인 건강관리 서비스를 구축하여 발병 가능한 질환을 예측하고 예방하는 방안을 제시하려는 시도들이 정부와 산학연 협업을 통해 진행되고 있다. 특히 보건복지부 산하 4개 기관인 건강보험심사평가원(이하 심평원), 건보공단, 국립암센터, 질병관리본부 간의 데이터 연계를 통한 정책 개발 등의 공익연구를 위한 시범 사업 등이 진행 중에 있다.
대한소화기학회에서는 보건 의료 빅데이터 연구를 통해 적정하고 비용-효과적인 진료를 위한 근거를 제시하고 빅데이터 분석 체계를 확립하며 회원에게 공익 연구 계획 및 실현 기회를 제공한다는 목표를 정하여 2015년 빅데이터연구위원회를 구성하였다. 본고에서는 위에 정의한 건강보험 빅데이터를 이용한 임상 연구의 설계에서 논문 작성까지 알아야 할 단계별 지식, 실제 임상 활용 그리고 향후 연구 방향과 전망에 대하여 기술하고자 한다.
본 론
건강보험 빅데이터의 자료원과 변수 구성
건강보험 정보의 구성
건보공단에서는 공익연구 목적으로 국민 건강 정보 자료(national health information database, NHID)를 구축하여 제공해 오고 있다. NHID에는 전 국민 건강보험 기반으로 축적된 건강보험 가입자의 인구학적 정보와 보험료, 의료기관 제공자가 제출한 진료 청구내역, 건강검진 수진 내역, 의료기관 정보 등을 포함한다(Table 1). 아울러 최근에는 통계청에서 수집한 사망 일자 등이 추가되었다. NHID는 심평원 청구 자료를 기본으로 하여 의료기관의 의무기록과는 차이가 있으며 자격자료에는 성별, 연령, 지역, 소득 분위 등 사회경제적 변수 등이 있다. 진료 자료는 의료비 청구과정에서 수집된 입원과 외래 기록(주 및 부상병명, 입원 및 내원 일수, 진료비 등), 처방 내역(처치, 수술, 약제, 치료 재료 사용 품목, 처방약 코드, 처방 일수, 처방 용량 등)을 포함한다. 일반 건강검진 자료는 흡연 음주 등 문진 내역 외에도 신체 검사 및 혈액 검사 수치를 포함하여 2002년부터 있지만 2009년 이후로 건강검진 항목이 개정되어 추가 또는 제외된 변수가 있음을 유의해야 한다. 2007년 이후로 40세와 66세에는 생애전환기 검진 자료가 별도로 구축되어 있다. 요양기관 자료는 의료기관 관리를 위한 자료로 의료기관 종별, 인력 및 장비 정보를 포함하고 있다.
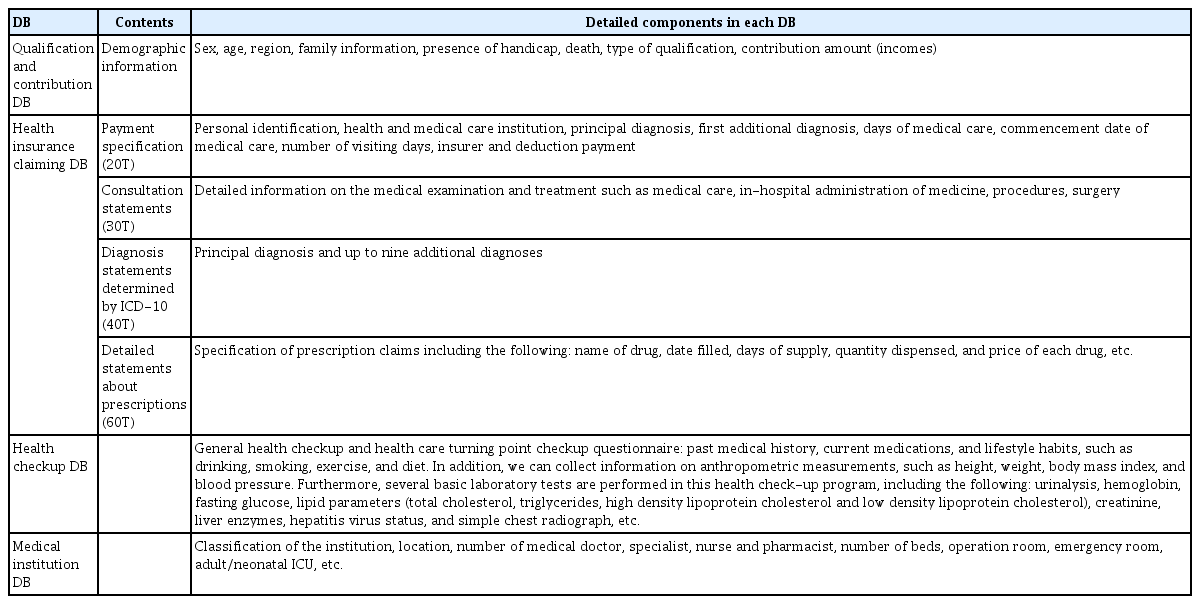
Components of claiming data in the national health insurance service
건강보험 빅데이터 자료원
현재 건보공단에서는 전 국민 대상의 연구가 가능한 맞춤형 자료와 전 국민 중 특정 조건으로 임의 추출한 코호트 자료 두 가지 형태로 제공하고 있다(국민건강보험공단의 빅데이터 자료 공유서비스, https://nhiss.nhis.or.kr/bd/ab/bdaba002cv.do). 후자에는 NHID 중 일부를 표본 추출하여 백만 코호트라 불리는 표본 코호트 자료를 포함하여 건강검진 코호트 자료, 노인 코호트 자료, 직장 여성 코호트 자료, 영유아검진 코호트 자료가 구축되어 있다. 초보 연구자에 익숙한 표본 코호트 자료는 2002년 1년간 건강보험 및 의료급여 수급권자 자격을 유지한 전 국민 2%에 해당되는 100만 명으로 구성되어 전 국민 대상 맞춤형 자료를 가지고 연구하기 전 일종의 시범 연구로 이미 많은 연구가 진행되었다. 2017년에는 단점을 보완하고자 버전 2가 구축되었는데, 이는 2002년 대신 2006년 자격 유지자로 100만 명 대상이 변경되었고, 추적 관찰을 2015년까지 확장함과 동시에 2002년까지 과거 이력을 확인할 수 있어 장기 추적 결과를 분석할 수 있다. 아울러 표본 코호트에는 통계청 사망 사유 정보가 있어 특정 사망에 대한 연구가 가능하다. 이 외 내과 관련된 코호트는 2002-2003년 자격 유지자들 중 일반 건강검진 수검자들을 대상으로 10% (51만 명)를 추출한 건강검진 코호트와 2002년 만 60세 이상 자격 유지자들 중 10% (55만 명)를 추출한 노인 코호트 자료를 들 수 있다.
연구 설계에 따른 자료 선택과 한계점
건강보험 빅데이터를 이용한 임상 연구 전 설계 단계에서 연구 유형과 목적에 맞는 자료를 얻을 수 있는지를 반드시 고려해야 한다. 건강보험 자료로 가장 많이 이용되는 연구설계는 환자 대조군 연구와 코호트 연구이다. 두 연구의 차이점은 임상 결과 발생 시점이 어디에 있는가인데, 후시점에서 질병 발생군과 비발생군으로 나눈 뒤 과거에 위험인자 노출력을 확인하는 것이 환자 대조군 연구이며, 치료 등의 중재 여부에 따른 효과를 입증하기 위하여 선시점에서 위험인자 또는 중재 노출력에 따라 중재군과 비중재군을 구분하고 두 군 간 질병 발생의 위험도를 평가하는 것이 코호트 연구이다. 연구 설계별로 맞춤형 자료 또는 표본 코호트 자료를 선택해야 하는데 유병률이 비교적 높은 질환은 임의 추출된 표본 코호트 자료만으로도 대부분 연구 목적을 달성할 수 있어 추천되며 자료 크기가 상대적으로 작아 집단 설정 등의 운용과 분석이 매우 자유롭다. 반면에 유병률이나 발생률이 낮은 질환은 전 국민을 대상으로 하는 맞춤형 자료를 신청하는 것이 유리하다. 맞춤형 자료의 경우 연구 목적에 맞도록 환자 대조군 또는 중재 여부에 따른 코호트의 집단 설정이 필요하다. 특히 후향적 코호트 연구에서 중재 여부에 따라 중재군을 특정 집단으로 규정하고 비교를 위한 비중재군을 설정할 때는 논문 투고 시 흔히 지적되는 선택 비뚤림을 피하기 위해 중재군과 가장 유사한 특성을 보이는 대상을 인위적으로 선정하는 단계를 알고리즘으로 명확히 제시해야 한다[2]. 이 외에도 연구 설계 유형 중 비교적 간단한 단면 연구(cross-sectional study)는 표본을 추출하여 관심 질환의 발병 여부와 위험요인을 동시에 조사하는 방법으로 초보 연구자가 시행하기에 적절하다.
건강보험 자료의 단점은 의무기록과 달리 상세한 임상 정보가 없으며 인과 관계를 설명할 수 있는 시차별 의료 행위의 구분도 어렵다. 예로써 입원 기간 대장내시경 검사로 인한 천공으로 수술을 받았다면 묶음 단위로 청구되므로 다른 원인의 천공으로 수술을 받고 대장내시경을 확인한 것과 구분이 어렵다. 또한 새로운 시술이나 미용 등의 비급여 진료는 포함하지 않고 자비로 시행한 건강검진 결과도 알 수가 없다. 따라서 연구 목적에 합당한 자료 추출이 가능한지를 전문가의 자문을 받아 면밀하게 검토한 후에 적합한 연구 주제를 설계해야 한다. 예로써 Helicobacter pylori 균 관련 연구는 검사 여부는 코드로 알 수 있으나 감염이나 제균 성공 치료 결과는 알 수 없어 Helicobacter pylori 감염률이나 제균율에 대한 연구는 현재의 자료로는 진행되기 어렵다. 또한 제한된 건강보험 자료 변수로부터 완벽하게 질환을 조작적으로 정의하기는 불가능하므로 이전 연구를 통해 필요한 질환의 조작적 정의를 확인해야 하고 이를 위해서는 학회 기반의 인증된 질환별 조작적 정의를 마련한 후 이를 각 기관의 의무기록과 대조하여 조작적 정의의 정확도를 검증하거나, 질환별 코호트 구축이 선행되어야 한다.
연구 설계 단계에서의 고려 사항
건강보험 빅데이터를 이용하여 최선의 결과를 얻기 위해서는 연구 설계 단계에서 고려할 사항들이 있다. 첫 번째는 연구 내용이 공익 목적에 부합해야 한다. 이를 만족하지 못하면 자료 제공 심의 과정에서 승인 받기가 어렵다. 두 번째는 연구 대상을 적절히 선정해야 하는데 이를 위해서는 코드를 이용한 조작적 정의가 선결되어야 한다. 또한 해당 조건을 정확히 만족하는 연구 대상을 설정해야 하는데 이에 따라 표본 자료나 인구집단 전체 자료를 선택해야 하며 후자의 경우 정교하게 설정한 특정 조건을 만족하는 코호트 등으로 구분된다. 이러한 자료들은 규모가 작은 검증된 의무기록 등을 통해 타당성 또는 재현성을 입증해야 좋은 연구 결과를 얻을 수 있다. 세 번째는 위의 기본 자료들에 더하여 다양한 자료원을 연계한다면 경제사회적 의미나 정책 활용 측면에서 연구 가치를 향상시킬 수 있다. 예로써 대장암 검진 연령 이슈에 있어 40대나 80대를 대상으로 일반 건강검진 자료, 국가 암 검진 자료, 자격 및 요양기관 자료에 암 등록 자료를 연계하여 부수적인 진료내역 등 다양한 정보를 연계함으로써 파생되는 많은 추가 결과를 얻게 된다. 네 번째로 고려할 점은 코딩으로 진행되는 빅데이터 분석이 올바른 결과인지 단계별 점검이 필요하므로 국가에서 발표하는 통계청 자료 같은 적정한 참고치를 활용하여 분석의 적정성을 검토하는 과정이 중요하다. 행정적인 고려사항으로 NHID는 건강보험자료공유서비스(http://nhiss.nhis.or.kr)를 통해 연구계획서 및 연구윤리심의위원회(Institutional Review Board, IRB) 승인 또는 심의 면제 확인서가 필요하다. 자료 제공 심의위원회를 통해 제공 여부가 결정되며 최근에는 많은 수요로 인하여 신청 후 자료를 받는 데 최소 6개월 이상 소요되는 점도 고려 대상이다. 따라서 빅데이터 연구에는 팀 구성이 필요하여 임상 연구자, 자료 분석 연구원과 통계 전문가가 최소 팀 단위가 되며 여기에 분석 경험이 많은 자문가로부터 자문을 받는 것이 바람직하다.
건강보험 빅데이터를 이용한 논문 작성
모든 논문과 같이 빅데이터 논문의 서론에도 연구 배경과 필요성을 논리적으로 기술하게 된다. 기존의 소규모 연구로는 결론을 얻기 어려운 연구주제를 설정하고 장점인 빅데이터를 이용한 당위성을 충분하게 설득력 있게 기술한다. 연구방법에서 빅데이터 자료를 신뢰할 수 있는지가 논문의 수준을 결정하는 중요 근거가 되므로 이미 게재된 기존의 자료를 이용한 논문을 이용하는 것이 가장 현명한 방법이다. 건강보험 자료는 전 국민의 97%가 가입되어 있고 대상자가 중복되지 않으며 의료기관 이용 정보가 누락되지 않는 신뢰도 높은 자료라는 장점이 있다[3,4].
건보공단 자료는 건강보험자료공유서비스(http://nhiss.nhis.or.kr)를 통해 신청할 수 있으며 영문 홈페이지 주소를 논문에 게시하기도 한다. 자료를 신청하려면 위의 홈페이지에 연구자 등록과정을 거쳐 연구계획서 및 IRB 승인(또는 심의 면제) 확인서를 업로드해야 한다. 자료 제공 여부는 공단 자료 제공 심의위원회를 통해 최종적으로 결정되는데, 제공이 결정된 연구에 대해서는 표본 연구 자료의 경우 원격 연구 포털을 통해, 맞춤형 연구 자료의 경우는 원주 본부와 각 도별 분석 센터를 통해 접근과 분석이 가능하다. 현재 자료 제공 심의위원회를 통해 승인된 연구는 2014년부터 2019년 현재 3천 건을 초과하였고 이를 활용한 논문 수는 2018년까지 SCI급 476편을 포함하여 616편으로 급증 추세이다. 대부분 빅데이터 논문에 들어가는 표준 코호트 자료와 일반 건강검진 자료의 코호트 소개 논문은 국제역학회지에 2편이 실렸으며 이들을 인용하면 국내 자료의 신뢰성을 대신할 수 있어 추천한다[5,6]. 이들 두 논문은 국제역학회지에서 2018년에 가장 많이 인용될 정도로 인용지수가 높다.
빅데이터 분석을 위한 조작적 정의는 빅데이터 연구의 가장 중요한 부분이며 여기에 오류나 혼란의 여지가 있다면 이후 분석 결과들은 신뢰하기 어렵다. 따라서 대상 환자를 선정한 기준으로 실 병원 자료를 이용하여 식별 코드나 알고리즘을 검증하는 것은 빅데이터 관찰 연구의 신뢰성 입증에 필수적이다[7,8]. 이미 발표된 논문에서 연구 대상 환자의 선정기준을 검증한 연구가 있다면 추가적인 검증 작업 없이 참고문헌으로 대체가 가능하다. 아울러 검증한 집단에서 조작적 정의에 대한 진단 정확도를 같이 제시하거나 기존에 질환별로 제시된 검증된 기준을 인용하면 신뢰성을 더할 수 있다[9]. 만약 이전에 인정된 기준이 없어 새롭게 선정기준을 정의해야 한다면 많은 연구자의 동의를 얻을 수 있게 설득력 있는 설명이 필요하다. 또한 연구에 사용된 위험 요인에 노출 여부, 임상 결과, 시술 또는 수술의 시행, 투약 등을 정의하는 방법도 상세히 기술해야 한다. 예를 들면 어떤 질환이 재발한 경우는 어떤 코드로 확인하였는지, 흡연은 어떻게 정의하였는지, 추적 관찰 중에 수술을 받은 경우는 어떻게 확인하였는지 등이다. 결과에서는 연구에서 의도하였던 목적에 맞추어 명확하게 기술해야 하며 빅데이터의 장점인 분석대상자 수가 많은 점, 추적 관찰 기간이 긴 점 그리고 세계 유일의 독창성 있는 코호트 구축 등을 명확히 표현하면 좋다. 특히 자료에서 처음 추출한 전체 환자 중에 선정 및 제외 기준에 따른 전반적인 대상자 선정 과정을 이해하기 쉽도록 흐름도로 명확히 제시해야 한다[10]. 연구 방법에 있어 건강보험 빅데이터는 무작위 배정을 통한 연구는 불가능하다. 따라서 후향 자료 분석의 단점을 보완하기 위해서는 혼란 변수 보정이나 다변량 회귀분석, propensity score analysis 등의 분석 기법을 흔히 이용하게 된다[11].
고찰에서는 분석 결과의 가치와 의미를 체계적으로 기술할 필요가 있다. NHID는 특정 목적으로 수집된 자료가 아니어서 오류가 생길 수 있다는 제한점을 비교적 상세히 기술하는 것이 좋다. 흔한 오류들로는 진단명 입력이나 완전한 조작적 정의에 기인한 대상자 선정과 결과 판정이 부정확할 수 있다. 빅데이터는 연구에 필요한 변수가 누락되거나 분석에 필수적인 주요 임상 자료를 얻지 못하는 경우도 있다. 예를 들면 암 환자의 경우 암의 병기와 병리 결과는 알 수 없다. 누락된 자료가 전체 결과에 영향을 주는 혼란 변수일 경우에는 큰 제한점이 되며 이에 대하여 충분히 설명해야 한다[12]. 기본적으로 NHID는 전 국민을 대상으로 한 자료이지만 상황에 따라 의료기관을 이용하지 않는 경우도 있어 의료기관 이용 대상자만의 자료를 분석하므로 발생률 같은 실제 질병 양상과는 차이를 보일 수 있다. 논문 심사 지적 사항에는 빅데이터 연구의 제한점 자체가 많으므로 다양한 관련 논문을 충분히 검토하여 연구의 제한점을 잘 극복하기 위한 방안 마련에 많은 노력이 필요하다.
건강보험 빅데이터를 이용한 최신 연구 동향
건강보험 빅데이터 연구는 가진 자료의 특성을 반영한 주제에 맞는 연구 설계가 필요하다. 이에 적합한 임상 연구 유형은 첫째, 단면 연구(cross-sectional study)나 역학 연구, 둘째, 환자-대조군 연구(case-control study), 셋째, 코호트 연구(cohort study)를 들 수 있다. 역학 연구의 예로 대한소화기학회 빅데이터 위원회에서는 지난 10여 년간 국내 진단 및 치료 대장내시경 건수가 10배 이상 급속도로 늘었고 특히, 대장 폴립 절제 치료 내시경 건수가 주로 1차 기관에서 증가함을 보고하였다[13]. 단순한 역학 단면 연구라도 새로운 시각의 창의적인 정책 제안을 할 수 있는 주제라면 영향력이 큰 학술지에 게재되기도 한다. 최근 국내 장애인 여성에서 장애 정도와 유형에 따라 자궁경부암 검진 참여율에 차이를 보인다는 내용이 임상암학회지에 게재되었다[14]. 두 번째 유형으로 환자-대조군 연구가 흔한데 최근 본 연구회에서 일정기간 대장암이 발생한 환자와 암이 없는 대조군에서 이전의 과거 예방 인자로서 대변 잠혈 검사나 대장내시경에 노출 여부를 오즈비로 평가하여 대장암 환자에서 과거 검진 시행 여부가 암 예방에 도움을 준다는 연구를 보고하였다. 세 번째 유형인 후향적 코호트 연구는 과거 기간에 일정 조건에 해당되는 인구집단 대표 일부를 설정하고 이후 위험 또는 예방 인자에 대한 노출 여부에 따른 질병의 발생 위험도를 hazard ratio로 평가하는 유형이다. 인구기반 후향 코호트 연구의 한 예로 대만의 Su 등[15]은 2001-2005년 사이 인구집단 전체에서 200만 명을 무작위 추출해서 이들 중 C형 간염이 있는 1만여 명과 간염이 없는 4만여 명의 대조군을 설정하고 2009년까지 림프종의 발생을 추적하여 C형 간염군에서 림프종 발생이 두 배 이상 높음을 보고하였다. 연구 유형의 조합도 가능한데, 인구기반 코호트 내 환자-대조군 연구를 예로 들 수 있다. Tsai 등[16]은 1998년에서 2011년 사이 100만 명을 대표 집단으로 설정하고 간경변이 있는 연구 대상을 추출하였다. 이후 간성뇌증이 발생한 군과 발생하지 않은 군을 1:1로 환자-대조군으로 분류하여 추적 기간 동안 간성뇌증 발병군에서 중성자펌프 산분비억제제의 복용 기간이 길었고 복용기간이 길수록 간성뇌증 발병률이 높음을 보고하였다.
건강보험 빅데이터는 전 인구집단 전체의 자료를 포함하므로 제한된 자료로는 결론짓기 어려운 미충족 연구 수요를 해결할 수 있다. 예로써 대장암 검진의 시작 연령은 전 세계적으로 대부분 45-50세, 종료 연령은 75-80세로 권고하고 있지만 실상 이에 대한 근거는 명확하지 않다. 대개는 대변 잠혈 검사의 무작위 비교 연구가 45-50세 이상을 대상으로 대장암 발생이 이 시기에 증가한다는 점 그리고 검진의 종료시기는 기대 여명이 10년 전후 남았거나 대상자의 질환력 등 신체 위험도를 고려하여 권장하는 것으로 되어 있다. 따라서 40대에서 대장내시경 등의 검진이 대장암 발생이나 사망을 줄인다는 후향 코호트 분석이나 80세 이상에서 이차 예방인 대장내시경 폴립 절제를 통한 생존 향상 등의 이득 등에 대한 연구가 진행 중에 있어 대장암 검진의 대상 연령을 결정하는 실증 근거를 국내 자료로 제시할 수 있을 것이다. 건강보험 빅데이터 연구는 인과관계보다는 연관성 분석에 국한된다는 단점이 있었으나 최근 빅데이터의 분석 시점을 고려한 인과관계 분석 연구들도 속속 발표되고 있다. 국내 심방세동 환자에서 기존의 와파린 치료군과 endoxaban 치료군의 아군 분석을 통하여 허혈성 뇌졸증, 사망 등의 임상 결과를 분석한 논문이 미국심장학회지 저널에 실리기도 하였다[17]. 이 연구를 통해 영향력 지수가 높은 학회지 게재와 연구회 등의 검증을 거친 질환 코호트가 구축이 되면 이를 기반으로 다양한 후속 연구들로 연결되어 해당 분야의 연구를 선도하는 연구자 그룹이 형성되는 장점이 있다[18].
최근 나타난 흥미로운 빅데이터 연구 영역의 하나는 변동성 분석이다. 즉 일정 기간의 측정치 변화량을 토대로 대상군을 구분하여 사망과 주요 질환의 임상 결과를 hazard ratio로 제시하는 연구이다. 예로써 국내에서 Kim 등[19]이 콜레스테롤 변동성에 따라 향후 사망, 심근경색, 뇌졸중의 위험도가 증가하는 것을 분석한 것을 들 수 있다. 이 연구 역시 변동성 변수 영역을 개척하여 콜레스테롤 이 외에도 혈압, 혈당, low-density lipoprotein-cholesterol 변동성이 심혈관 질환 임상 결과에 미치는 영향 등 다양한 후속 연구 결과를 이끌었다[20,21]. 향후 건강보험 빅데이터에 기반한 연구의 방향을 가늠해 보자면 우선 건강보험 빅데이터는 국가 기반의 전 국민 자료이므로 공익적인 목적으로 활용되어야 한다는 점을 인식해야 한다. 따라서 실질적인 국민 건강 증진과 인류 보건 향상이라는 목표를 염두에 두고 다양한 연구 방법론들의 도입을 기대해 볼 수 있다. 여기에는 아직 국내 미개척 분야인 의료비 절감을 위한 경제성 평가나 후향적 의료 비용-효과 분석, 빅데이터를 토대로 얻은 시험 분석 결과를 실제 의료기관에서 검증하는 공공-민간 또는 국가간 연계, 최근 각광받는 deep learning 기반 모델링, 의약품뿐만 아니라 의료기기 등 산학연 헬스케어 융합 연구 등을 생각할 수 있을 것이다.
결 론
보건 의료 빅데이터를 활용한 분야 중 일부는 이미 일상생활뿐 아니라 산업현장에서도 빠르게 응용되고 있다. 특정 분야에서는 근거 중심의 빅데이터를 활용한 기술 발전에 힘입어 임상전문가의 경험보다 훨씬 정확하고 빠른 판단으로 빅데이터 기반의 의사결정을 통해 질병 진단과 치료해 주리라는 인식을 주고 있다. 아울러 빅데이터는 기존의 의료 패러다임을 전환시켜 진정한 맞춤 의학시대를 열 것이라는 기대도 불러일으키고 있다. 하지만 여러 분야의 다양한 빅데이터 수집과 활용을 통한 연구에 대한 의문도 제기되는데, 이는 질적 제한점을 간과할 수 없기 때문이다. 따라서 빅데이터 연구 결과를 의료 행위의 근거로 사용하기 위해서는 극복해야 할 과제들이 많다. 또한 향후 적절한 기술 보완이 이뤄지기까지는 빅데이터 분석 과정의 과학적 신뢰와 결과 도출시 합당성을 판단하는 과정에 임상의료 전문가의 개입과 해석이 요구된다. 따라서 보건 의료 빅데이터 연구는 연구자 개인의 아이디어와 노력만으로는 목표를 달성하기 어렵다. 데이터 사이언티스트, 역학 및 통계 전문가, 임상 연구자로 팀을 구성하여 단계별로 정기 모임을 통해 연구설계부터 전문가 자문과 팀 구성원 간의 긴밀한 논의가 필요하다. 아울러 국민 전체 또는 인류를 위한다는 소명을 바탕으로 자료를 제공하는 정부기관, 국민을 대표하는 이익단체, 정책입안기구 등과 협력을 통해 사회를 보다 건강한 공동체로 만들려는 하나의 시각이 요구된다. 이러한 중심에서 공익 연구를 주도하는 보건 의료 빅데이터 연구자의 역할은 매우 중요할 것이다. 연구자 역량을 최대화하기 위해서는 국민의 개인정보 자기결정권이 침해받지 않도록 보호하는 범위 내에서 자료를 충분히 활용하기 위한 안전하고 효과적인 법과 제도 개선, 기술적 행정적 조치가 전제되어야 한다. 이러한 공익 연구결과물을 통해 국민 삶의 질 향상과 더불어 새로운 부가가치 창출로 이어져야 함은 말할 나위도 없다. 때마침 보건복지부 산하 4개 기관인 심평원, 건보공단, 국립암센터, 질병관리본부 데이터 연계를 통한 정책 개발을 목표로 보건 의료 빅데이터 R&D와 공익연구 활성화 연구 개발 사업들이 진행되는 점은 연구자에게 좋은 기회와 동기를 부여하고 있다.
향후의 바람직한 빅데이터 임상 연구는 국가 연구비를 기초로 학회 또는 연구회가 주도로 공익 연구안을 이론적으로 고안하고 제시하고 다양한 정부 연구 인력의 자문이나 협력을 통해 분석을 수행하는 공동 연구 협력으로 더 큰 부가가치를 창출할 수 있을 것이다. 이러한 접근으로 복잡하고 방대한 자료의 분석을 보다 수월하게 할 수 있고 공익기반의 연구로 실제 국민에게 도움되는 연구 방향을 꾀해야 한다. 이외에도 연구자 접근성을 높이기 위한 내부 클라우드 구축, 원격서비스 계정 확대가 시행될 예정이므로 이를 고려한 연구 디자인을 설계하는 것이 바람직하다. 아울러 인공지능 등 4차 산업혁명과 맞물려 관련 연구가 획기적으로 증가할 것이다. 이런 다양한 시도를 통해 공익 목적의 자료 활용으로 전 국민 건강 수준이 향상되어 결국 자료 제공의 당위성과 필요성이 다시 부각되는 선순환이 이루어지기를 기대한다.
Acknowledgements
This research was supported by the National Research Foundation (NRF) of Korea grant funded by the Korea government (Ministry of Science and ICT) (No. 2019R1A2C1007859) and a grant from the National R&D Program for Cancer Control, Ministry of Health & Welfare, Republic of Korea (HA17C0046).